All About Transcription for Real-Time (Live) Audio Streaming

August 22, 2022 in Best Practices

Real-time streaming transcriptions involves taking audio that's being generated live and transcribing it into text. One of the major use cases for real-time streaming is live captioning. As speakers talk, text is generated and displayed on the screen. Real-time streaming can also transcribe or caption pre-recorded media that's presented during an event.
How Does Real-Time Streaming Transcription Work?
Real-time streaming is similar to pre-recorded transcription. The audio goes through the same speech model for transcriptions but the audio input and output is configured differently. Input is sent through a live streaming protocol like websocket. The output can be text over websockets also. Adding speech understanding feature to the output stream is mostly done post transcription processing. Post transcription processing can include diarization, profanity filtering, redaction, and other features depending on the speech recognition and understanding provider. Here's a code sample of how we do real-time transcription with Deepgram:
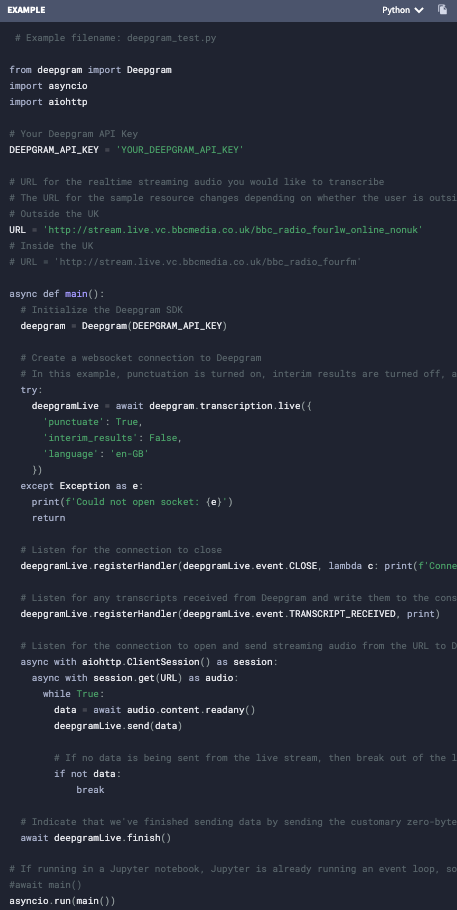
You can get the full instructions and code in our streaming quickstart guide.
Why is Live Audio Streaming Transcription Used?
Real-time streaming transcription is used to get immediate transcriptions of an audio stream, which is then provided to a human reader or a machine. For a human reader, this is called live captioning. The text appears within seconds of the speaker finishing a word. Captioning has many benefits, but one compelling example is to allow hearing-impaired individuals to follow what a speaker is saying.
For a machine, real-time streaming transcription can be used to transcribe a user's audio responses to an IVR, voicebot, or virtual assistant to continue a human-to-machine conversation. Real-time streaming can also be used to search for important information in a conversation as it's happening, and then provide a contact center agent with on-screen tips or hints to help solve a customer's issues or recommend an upsell.
What Are the Use Cases for Real-Time Streaming Transcription?
As noted above, live audio streaming has a number of human and machine use cases, including:
Agent assistance - Having an AI read the transcription data can provide support suggestions and upsell recommendations to an agent on the line in real time.
IVR/Voicebots/Virtual assistants - Quickly transcribe a user's responses so the AI can determine what is said and the intent of it in order to respond quickly and accurately.
Live captioning - Provide captioning of a live event, lecture, concert, or webinar for the hearing impaired or others who prefer reading instead of just listening. This can be for in-person or online participants.
Meeting summary and analytics - Transcribing and analyzing a meeting in real-time allows quicker post-meeting actions, i.e., action items identified, meeting summary shared, and any sales coaching opportunities identified.
Personal captioning - Provide captioning so that a hearing-impaired patient can understand what's happening.
Real-time analytics - Stream the audio for transcription and analysis so any issues can immediately be resolved, for example, if an agent did not repeat the compliance statement.
Sales enablement - Stream the transcription to an AI to gauge the salesperson's sales pitch and recommend better closing tactics immediately after a call or meeting.
Video Gaming - Stream the conversations between players for easier communication and to monitor inappropriate language.
What Are the Metrics for Real-Time Streaming?
Similar to transcribing pre-recorded audio, accuracy is the main metric. Word Error Rate (WER) is perhaps the most commonly used quantitative metric for evaluating and comparing the performance of speech-to-text (STT) solutions for accuracy. It is defined as:
WER = S + D + I / N
S is the number of word substitutions
D is the number of word deletions
I is the number of word insertions
N is the number of total words in ground truth transcript (Ground truth transcript is a human transcribed passage)
The lower the WER, the better the transcription is in terms of word accuracy. Accuracy is 1 - WER. We asses that if WER is below 20%, transcripts tend to be more human readable as humans can decipher mistakes and fill in missing words. Anything over 20% would be difficult to read and understand. For machines, our goal is to have a WER of below 10%, which is what we have heard is necessary from our voicebot customers. Another metric used to gauge accuracy is Word Recall Rate/Word Recognition Rate (WRR). WRR measures the percentage of words in the ground truth text that were correctly predicted, or matched (i.e., true positives). This does not include insertions (where there isn't a word in the ground truth, but the transcription has one).
WRR = # word matches / # of words
The higher the WRR, the better the transcription is in terms of word accuracy. WRR is again not the perfect metric as it does not include incorrect insertion of words. We assess that if WRR is over 80%, it also tends to be human readable. The third most important metric for real-time streaming is automatic speech recognition (**ASR) latency**, which is how fast a word appears after the speaker says the word. Unfortunately, latency has various components that you may or may not be able to control. A simple latency formula for real-time streaming in the cloud is:
Latency (milliseconds) = ASR latency + Internet latency
ASR latency is how long it takes to transcribe the audio.
Internet latency is how long it takes for the audio data to get to the ASR servers and how long it takes the text data to get back to you.
For example, if you are building a voicebot, you want to minimize the wait time of the user from when a word is spoken to when the AI voicebot responds. Within that wait time, there are a lot of processes going on. If you want a true human-like voicebot experience, all processing must be done in milliseconds; thus, the ASR latency of that process must be in milliseconds. Internet latency can be minimized with an on-premises deployment of the ASR solution.
Real-time Streaming Transcription with Deepgram versus Others
Now that you know more about how to gauge real-time streaming transcriptions. Here are the major benefits of Deepgram over other ASR providers:
Highest accuracy - Our various speech models have shown to be highly accurate for various use cases. Hear and see our accuracy results versus Google and Amazon.
Lowest ASR latency - Our latency is under 300 milliseconds, which is faster than all other competitors. Amazon, for example, has a latency of 2-3 seconds.
Support for all language and use-case models - Our real-time streaming supports all our languages and use-case models. Some ASR providers limit you to a few languages or use case models.
Choice of deployment - We offer cloud or on-premise deployments to reduce any Internet latency. All with the same accuracy, features, and tools but in a Docker container.
Get started with our real-time streaming guide, SDKs, or our API references—or you can immediately try out our real-time features on our Console-sign up and get $150 in credits to give Deepgram a try.
Newsletter
Get Deepgram news and product updates
If you have any feedback about this post, or anything else around Deepgram, we'd love to hear from you. Please let us know in our GitHub discussions .
More with these tags:
Share your feedback
Was this article useful or interesting to you?
Thank you!
We appreciate your response.



