

Share
In this blog post
- An Introduction to Audio Data
- Ways To Use Audio Data
- Recording Audio Data With Python
- Playing Audio Data With Python
- Clipping Audio Data With Python
- Manipulating Audio Data Sampling Rates With Python
- Changing Volume of Audio Data with Python
- Combining Two Audio Files With Python
- Overlay Two Audio Files With Python
- Changing Audio Data File Formats With Python
- Transcribe Audio Data With a Web API
- Summary of the Best Python Tools for Manipulating Audio Data
- Further Reading
Python provides us with many packages to manipulate audio data, but they don’t all work. As Python developers, we’re all familiar with the usual challenges - solving environments, compatibility between versions, and finding the right packages. This post covers how to do all of that for working with audio data. You can find a GitHub repo here with all the samples discussed below.
Note that this post is written using Python 3.9 as many audio packages have not yet been upgraded to work with 3.10 or 3.11. In this post we’ll cover:
An Introduction to Audio Data
What is audio data? Simply put, audio data is any data format that comes in the form of audio. At a fundamental level, there are not many ways to represent sound. The large number of audio data file types is due to the number of approaches to compress and package the data. Let’s take a look at two fundamental concepts before we jump deeper - sampling rates and types of audio data formats.
What Is a Sampling Rate?
A sampling rate, sometimes also referred to as a frame rate, is the number of times per second that we measure the amplitude of the signal. It is measured in frames per second or Hertz (Hz). An ideal rate can be determined using Nyquist’s Sampling Theorem. Some common sampling rates are 16 kHz (common for VoiP), 44.1 kHz (common in CDs), and 96 kHz (common in DVDs and Blu-Ray).
Types of Audio Data
There’s one well known way to represent sound - using waves. However, computers can represent that data in many ways. The most common audio data file types are .wav and .mp3. The main difference between .wav and .mp3 files is that .wav files are not compressed and .mp3 files are. This makes .wav files great for when you need the highest quality audio and .mp3 files best when you need fast streaming.
Other file types include Audio Interchange File Format (AIFF), raw Pulse Code Modulation (PCM) data, and Advanced Audio Coding (AAC). AIFF is a file format developed by Apple to be used on Mac OS much like WAVE files were initially developed by Microsoft. PCM is the raw audio data format. AAC’s were meant to be the successor to MP3 files, but did not catch on as a replay format. However, it did catch on as a popular streaming audio format and is used by YouTube, iPhones, and Nintendo.
Ways To Use Audio Data
Audio data is becoming more and more ubiquitous. It’s created on phone calls, remote video meeting recordings, for music and videos, and so much more. How can we use all this audio data being created? We can layer sound bites for music, change the volume of different sound streams to make it easier to hear everyone from a VoiP call, or transcribe a call to read later. Of course, this only covers some of the things we can do with sound data, there are many other valuable ways to use audio that we haven’t even discovered.
Recording Audio Data With Python
Two of the most basic things you can do with audio data in Python are playing and recording audio. In the next two sections we’ll cover how to use two popular Python sound libraries to play and record audio data. First, we’ll take a look at how to record audio data with sounddevice and pyaudio.
Before we get started with the code, we’ll have to install the prerequisite libraries. PyAudio is a wrapper around PortAudio. The installation will be different for Windows and Mac. On Mac OS, you can use brew to install portaudio after installing your X-Code tools. For Windows, see this answer on StackOverflow.
How to Install PyAudio (on Mac):
xcode-select --install
brew remove portaudio
brew install portaudio
pip install pyaudioIf you are having trouble, use this command instead to specify your build locations for portaudio:
pip install --global-option='build_ext' --global-option="-I$(brew --prefix)/include" --global-option="-L$(brew --prefix)/lib" pyaudioTo install python-sounddevice, run the line pip install sounddevice scipy in the command line. We will need scipy for downloading the streamed data and for later use.
Use PyAudio To Record Sound
In this example, we’re going to use PyAudio and the Python native wave library to record some sound and save it into a file. We’ll start by importing the two libraries and declaring constants. The constants we need to declare up front are the chunk size (the number of frames saved at a time), the format (16 bit), the number of channels (1), the sampling rate (44100), the length of our recording (3 seconds), and the filename we want to save our recording to.
From there, we create a PyAudio object. We’ll use the PyAudio object to create a stream with the constants we set above. Then, we’ll initialize an empty list of frames to hold the frames. Next, we’ll use the stream to read data while we still have time left in our 3 second timeframe and save it in the chunk size of 1024 bits.
We need to close and terminate our stream after 3 seconds. Finally, we’ll use the wave library to save the streamed audio data into a .wav file with the preset constants we declared above.
import pyaudio
import wave
chunk = 1024
sample_format = pyaudio.paInt16
channels = 1
fs = 44100 # frames per channel
seconds = 3
filename = "output_pyaudio.wav"
p=pyaudio.PyAudio()
print("Recording ...")
stream = p.open(format = sample_format,
channels = channels,
rate = fs,
frames_per_buffer = chunk,
input = True)
frames = []
for i in range(0, int(fs/chunk * seconds)):
data = stream.read(chunk)
frames.append(data)
stream.stop_stream()
stream.close()
p.terminate()
print("... Ending Recording")
with wave.open(filename, 'wb') as wf:
wf.setnchannels(channels)
wf.setsampwidth(p.get_sample_size(sample_format))
wf.setframerate(fs)
wf.writeframes(b''.join(frames))
wf.close()Record With Python-Sounddevice
Python-Sounddevice, or just sounddevice when you import it or install it through pip, is a simple sound recording and playing library. We can see below that it takes much less code to simply make a recording than pyaudio.
First, we import the libraries we need, sounddevice and the write function from scipy.io.wavfile. Next, we declare a couple constants for the sampling rate and the length of recording. Once we have those, we just record, ask sounddevice to wait, and then use scipy to write the recorded audio.
import sounddevice as sd
from scipy.io.wavfile import write
fs = 44100
seconds = 3
recording = sd.rec(int(seconds*fs), samplerate=fs, channels=1)
sd.wait()
write('output_sounddevice.wav', fs, recording)Playing Audio Data With Python
Playing audio data is the sister function to recording audio data. Only being able to record data would be almost useless. For this section, we’re going to use the same libraries we did above, pyaudio, and sounddevice. However, we will also need one more library for using sounddevice to play audio data, soundfile. We need to run this command in the terminal: pip install soundfile to install it.
Use Pyaudio To Play Audio
Once again, we’ll use the built-in wave library along with pyaudio to play some sound. We’ll use the recording we made above and the same chunk size. We will start our functionality by opening the file and creating a pyaudio object.
We will then use the pyaudio object to open a stream with specifications extracted from the wave file. Next, we’ll create a data object that reads the frames of the wave file in the specified chunk size. To actually play the sound, we’ll loop through the data file and write it to the stream while it is not an empty bit. Finally, we’ll close the stream and terminate the pyaudio object.
import pyaudio
import wave
# declare constants and initialize portaudio/pyaudio object
filename = 'output_pyaudio.wav'
chunk = 1024
wf = wave.open(filename, 'rb')
pa = pyaudio.PyAudio()
# create stream using info from the file
stream = pa.open(format = pa.get_format_from_width(wf.getsampwidth()),
channels = wf.getnchannels(),
rate = wf.getframerate(),
output = True)
# read in the frames as data
data = wf.readframes(chunk)
# while the data isn't empty
while data != b'':
stream.write(data)
data = wf.readframes(chunk)
# cleanup
stream.close()
pa.terminate()Play Audio With Python-sounddevice
Once again, we see the simplification of playing audio that sounddevice offers over pyaudio. Remember that both the playing and recording simplifications also come with the need to install and use two extra libraries though.
For this example, we will import the sounddevice and soundfile libraries. Then, we will feed the filename to soundfile to read us the data and the sampling rate. Finally, we use sounddevice to play the resulting sound and make the process wait while the sound finishes playing.
import sounddevice
import soundfile
filename = "output_sounddevice.wav"
data, fs = soundfile.read(filename, dtype='float32')
sounddevice.play(data, fs)
status = sounddevice.wait()Clipping Audio Data With Python
Now that we’ve covered the simplest acts of playing and recording audio, let’s move onto how to change the audio data. The first thing we’ll cover is clipping or trimming audio data. For this example, we’ll need to install two more libraries, pydub and ffmpeg-python. We can install these with pip in the command line as usual using pip install pydub ffmpeg-python.
Clip Audio With Pydub
As we will see here and further down the post, the pydub library is a swiss army knife of audio manipulation tools. To trim audio data with pydub, we only need the AudioSegment object. To start, we’ll define the first and last milliseconds we want to clip out. Then, we’ll load the audio file with AudioSegment.
To clip our audio file down, we’ll create a list that only contains the data from the start to the end millisecond in our audio file. Finally, we’ll use the export function of the AudioSegment object we extracted to save the file in .wav format.
from pydub import AudioSegment
# start at 0 milliseconds
# end at 1500 milliseconds
start = 0
end = 1500
sound = AudioSegment.from_wav("output_pyaudio.wav")
extract = sound[start:end]
extract.export("trimmed_output_pydub.wav", format="wav")Trim Audio Clips With FFMPEG
FFMPEG is a well known audio manipulation library, usually used in the command line. You can use the sys and subprocess libraries that are native to Python to use FFMPEG, but I find that using the SDK is easier and more satisfying.
Even though we had to install this SDK with pip install ffmpeg-python, we actually import it as just ffmpeg. The first thing we’ll do is get an input object. Then, we’ll use the ffmpeg.input object to call the atrim function and trim the recording down to 1 second. Next, we’ll create an output using the newly cut data. Finally, we’ll need to call ffmpeg to actually run the output call and save our file.
import ffmpeg
audio_input = ffmpeg.input("output_sounddevice.wav")
audio_cut = audio_input.audio.filter('atrim', duration=1)
audio_output = ffmpeg.output(audio_cut, 'trimmed_output_ffmpeg.wav', format='wav')
ffmpeg.run(audio_output)Manipulating Audio Data Sampling Rates With Python
Here’s where things get a bit trickier. Sampling rates play a huge part in how audio data sounds. When you’re changing the number of frames per second that represents a sound, a lot of funky things can happen. If not done right, it can affect the speed, the pitch, and the quality of your sound. For our examples, we’ll be using pydub and scipy. Both libraries we already downloaded earlier.
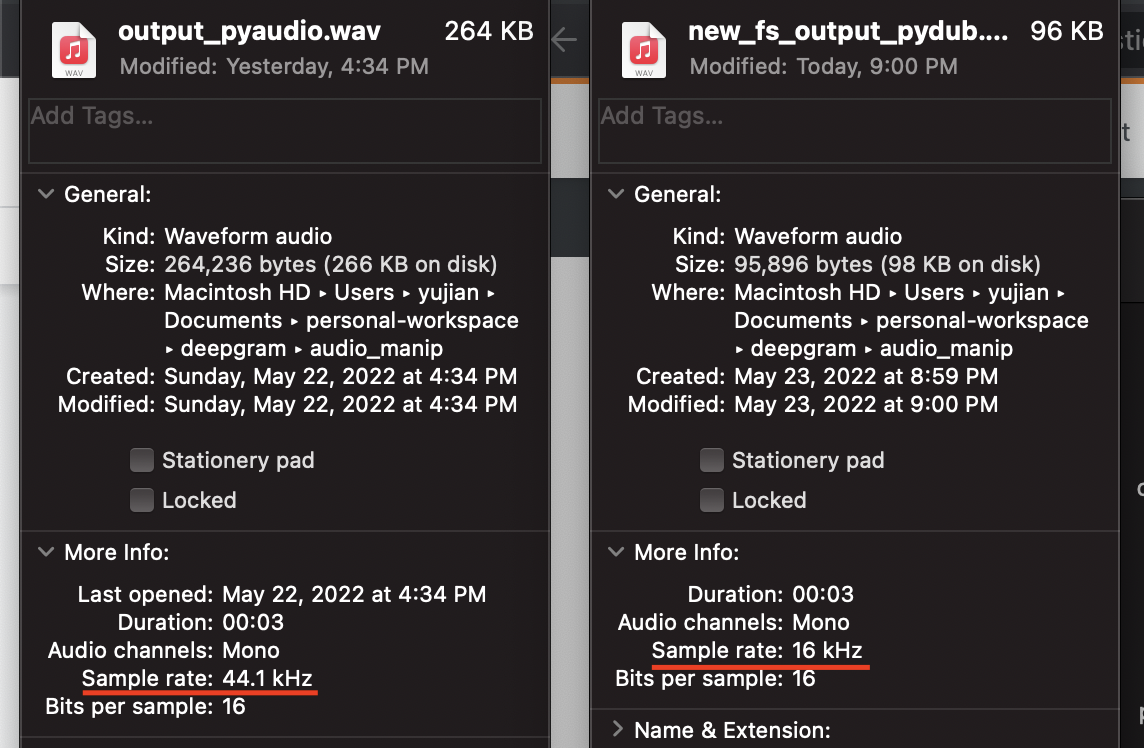
Pydub
As mentioned above, pydub has a variety of tools for manipulating audio data, and changing the sample rate safely is one of them. The AudioSegment object has a wonderful set_frame_rate command that can be used to set the frame rate of the audio segment without changing the pitch, speed, or applying any other distortions. To save it, we will use the export function again.
from pydub import AudioSegment
sound = AudioSegment.from_wav('output_pyaudio.wav')
sound_w_new_fs = sound.set_frame_rate(16000)
sound_w_new_fs.export("new_fs_output_pydub.wav", format="wav")Scipy
If you are so inclined and also mathematically skilled, you can apply your own sampling rate change with scipy. The most popular reasons to use scipy to customize your sampling is for advanced use cases like research, music, or special effects.
Read in the sample rate and audio data using wavfile. Using the read-in sample rate and a desired new sample rate, create a new number of samples. To do the resampling, we call on the resample function from scipy.signal. This resample function applies a fourier transform and may cause distortion. This is a much more advanced technique and should probably only be used if necessary.
from scipy.io import wavfile
import scipy.signal
new_fs = 88200
# open data
sample_rate, data = wavfile.read('output_pyaudio.wav')
# resample data
new_num_samples = round(len(data)*float(new_fs)/sample_rate)
data = scipy.signal.resample(data, new_num_samples)
wavfile.write(filename="new_fs_output_scipy.wav", rate=88200, data=data)Changing Volume of Audio Data with Python
The next four things we’re going to cover all use pydub. Partially because it is the easiest to use, partially because it is the only one that is updated enough to work with the latest versions of Python.
Changing volume with the AudioSegment object from pydub is extremely easy. After importing the libraries and functions we need and opening up the .wav file, the only thing we need to do is add or subtract from the object representing the open .wav file.
The play function plays both sounds, one after the other, so that we can hear that one is louder and the other is softer. We can save the files using the export function as we have been doing so far.
from pydub import AudioSegment
from pydub.playback import play
sound = AudioSegment.from_wav("new_fs_output_pydub.wav")
# 3 dB up
louder = sound + 3
# 3 dB down
quieter = sound - 3
play(louder)
play(quieter)
louder.export("louder_output.wav", format="wav")
quieter.export("quieter_output.wav", format="wav")Combining Two Audio Files With Python
We can also use pydub to combine two audio data files in Python. Once we open up the .wav files with AudioSegment, all we have to do to append them is add them. We can play the sound to make sure we got it and then export it into a file.
from pydub import AudioSegment
from pydub.playback import play
sound1 = AudioSegment.from_wav("louder_output.wav")
sound2 = AudioSegment.from_wav("quieter_output.wav")
combined = sound1 + sound2
play(combined)
combined.export("louder_and_quieter.wav", format="wav")Overlay Two Audio Files With Python
You’d think that overlaying audio data would be harder than combining them, but the AudioSegment object from the pydub library makes it quite easy. All we do is call the overlay function and pass it the sound we want to overlay and the position (in milliseconds) we want to overlay it at.
from pydub import AudioSegment
from pydub.playback import play
sound1 = AudioSegment.from_wav("louder_output.wav")
sound2 = AudioSegment.from_wav("quieter_output.wav")
overlay = sound1.overlay(sound2, position=1000)
play(overlay)
overlay.export("overlaid_1sec_offset.wav", format="wav")Changing Audio Data File Formats With Python
We’ve covered a lot of ways to manipulate audio data in Python from the basic playing and recording to overlaying different sounds. What if we just need our audio file in a different format? We can also use pydub to convert audio formats.
The AudioSegment object’s export function that we’ve been using in the sections above has the capability to define the output object’s format. All we have to do to save it as a different format is pass that format to the export function. In the example below, I’ve opened up a .wav file and saved it as a .mp3.
from pydub import AudioSegment
wav_audio = AudioSegment.from_wav("louder_output.wav")
mp3_audio = wav_audio.export("louder.mp3", format="mp3")Transcribe Audio Data With a Web API
Finally, we come to the last bit of audio data manipulation to be covered in this primer to audio data in Python. Having the transcription of an audio file can be useful for many reasons. You can use it to visualize your data, search for keywords from a library of audio files, or get inputs for Natural Language Understanding (NLU) models.
To transcribe your audio with a Web API, you’ll need to sign up for a free Deepgram API key and run pip install deepgram-sdk in your terminal.
We’ll be using asyncio to asynchronously make the API request. Before we create our function, we need to make sure that we have the API key and the file name. The function will initialize the Deepgram SDK, open the local file, and send it to the transcription endpoint. Then it will wait for the response and dump it into a JSON file formatted with a tab of 4 spaces. We will then both print the JSON result to the terminal and save it as a .txt file. Finally, we’ll use asyncio to run the function.
from deepgram import Deepgram
from config import dg_secret_key
import asyncio, json
DEEPGRAM_API_KEY = dg_secret_key
PATH_TO_FILE = 'louder_output.wav'
async def main():
# Initializes the Deepgram SDK
deepgram = Deepgram(DEEPGRAM_API_KEY)
# Open the audio file
with open(PATH_TO_FILE, 'rb') as audio:
# ...or replace mimetype as appropriate
source = {'buffer': audio, 'mimetype': 'audio/wav'}
response = await deepgram.transcription.prerecorded(source, {'punctuate': True})
json_obj = json.dumps(response, indent=4)
print(json_obj)
with open("transcribed.txt", "w") as f:
f.write(json_obj)
asyncio.run(main())Summary of the Best Python Tools for Manipulating Audio Data
Audio data covers a large swath of data that isn’t commonly thought about when it comes to data analysis and manipulation. In this post, we covered how to use some of the most up-to-date Python libraries for manipulating audio data.
We learned how to play and record audio data using pyaudio and python-sounddevice. How to trim data with pydub and ffmpeg, and how to resample data with pydub and scipy. Then we saw how we can use pydub as a swiss army knife of audio to change the volume, combine or overlay files, and change the file format. Finally, we saw how we can easily use the Deepgram SDK to transcribe audio data.
Further Reading
If you have any feedback about this post, or anything else around Deepgram, we'd love to hear from you. Please let us know in our GitHub discussions .
More with these tags:
Share your feedback
Was this article useful or interesting to you?
Thank you!
We appreciate your response.



