

If you have a podcast, or want to analyze podcasts, this is the post for you! We'll cover how to transcribe your local podcast recordings, those which are hosted online, and the latest episodes from podcast RSS feeds.
Before You Start
You must have Python installed on your machine - I'm using Python 3.10 at the time of writing. You will also need a Deepgram API Key - get one here.
Create a new directory and navigate to it in your terminal. Create a virtual environment with python3 -m venv virtual_env and activate it with source virtual_env/bin/activate. Install dependencies with pip install deepgram_sdk asyncio python-dotenv feedparser.
Open the directory in a code editor, and create an empty .env file. Take your Deepgram API Key, and add the following line to .env:
DEEPGRAM_API_KEY="replace-this-bit-with-your-key"Dependency and File Setup
Create an empty script.py file and import the dependencies:
import asyncio
import os
from dotenv import load_dotenv
from deepgram import Deepgram
import feedparserLoad values from the .env file and store the Deepgram key into a variable:
load_dotenv()
DEEPGRAM_API_KEY = os.getenv('DEEPGRAM_API_KEY')Finally, set up a main() function that is executed automatically when the script is run:
async def main():
print('Hello world')
if __name__ == '__main__':
asyncio.run(main())Generate a Transcript
Deepgram can transcribe both hosted and local files, and in the context of podcasting, files may also be contained within an RSS feed.
Inside of the main() function, initialize the Deepgram Python SDK with your API Key:
deepgram = Deepgram(DEEPGRAM_API_KEY)Option 1: Hosted Files
To transcribe a hosted file, provide a url property:
url = 'https://traffic.megaphone.fm/GLT8627189710.mp3?updated=1655947230'
source = { 'url': url }
transcription_options = { 'punctuate': True }
response = await deepgram.transcription.prerecorded(source, transcription_options)
print(response)Option 2: RSS Feed
To transcribe the latest podcast episode, use feedparser and select the first returned item:
rss = feedparser.parse('https://feeds.npr.org/510318/podcast.xml')
url = rss.entries[0].enclosures[0].href
source = { 'url': url }
transcription_options = { 'punctuate': True }
response = await deepgram.transcription.prerecorded(source, transcription_options)
print(response)Option 3: Local File
with open('icymi.mp3', 'rb') as audio:
source = { 'buffer': audio, 'mimetype': 'audio/mp3' }
transcription_options = { 'punctuate': True }
response = await deepgram.transcription.prerecorded(source, transcription_options)
print(response)Note that once you open the file, all further lines must be indented to gain access to the audio value.
Speaker Detection and Paragraphing
The generated transcript is pretty good, but Deepgram has two additional features which make a huge difference when creating podcast transcripts - diarization (speaker detection) and paragraphs.
Update your transcription_options:
transcription_options = { 'punctuate': True, 'diarize': True, 'paragraphs': True }Replace print(response) with the following to access a nicely-formatted transcript:
transcript = response['results']['channels'][0]['alternatives'][0]['paragraphs']['transcript']
print(transcript)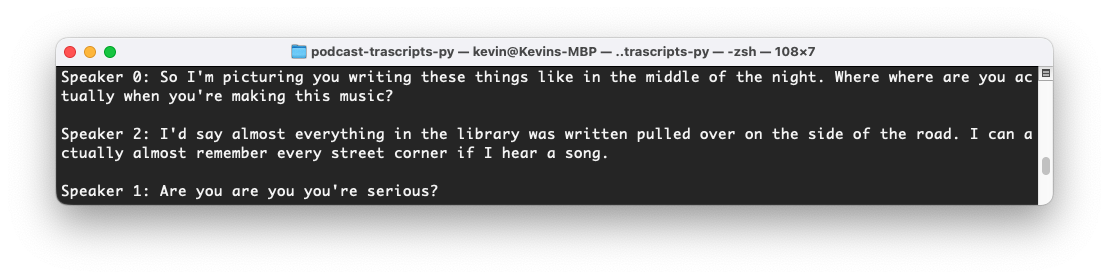
Saving Transcript to a File
Replace print(transcript) with the following to save a new text file with the output:
with open('transcript.txt', 'w') as f:
f.write(transcript)Wrapping Up
You can find the full code snippet below. If you have any questions, feel free to get in touch.
import asyncio
import os
from dotenv import load_dotenv
from deepgram import Deepgram
import feedparser
load_dotenv()
DEEPGRAM_API_KEY = os.getenv('DEEPGRAM_API_KEY')
async def main():
print('Hello world')
deepgram = Deepgram(DEEPGRAM_API_KEY)
# Option 1: Hosted File
url = 'your-hosted-file-url'
source = { 'url': url }
# Option 2: Latest Podcast Feed Item
# rss = feedparser.parse('rss-feed-url')
# url = rss.entries[0].enclosures[0].href
# source = { 'url': url }
# Option 3: Local File (Indent further code)
# with open('florist.mp3', 'rb') as audio:
# source = { 'buffer': audio, 'mimetype': 'audio/mp3' }
transcription_options = { 'punctuate': True, 'diarize': True, 'paragraphs': True }
response = await deepgram.transcription.prerecorded(source, transcription_options)
transcript = response['results']['channels'][0]['alternatives'][0]['paragraphs']['transcript']
with open('transcript.txt', 'w') as f:
f.write(transcript)
if __name__ == '__main__':
asyncio.run(main())If you have any feedback about this post, or anything else around Deepgram, we'd love to hear from you. Please let us know in our GitHub discussions .
More with these tags:
Share your feedback
Was this article useful or interesting to you?
Thank you!
We appreciate your response.



