

Personal language usage is a journey of learning and adapting, which certainly extends to terms you may not yet realize are non-inclusive or potentially profane to others. By detecting and pointing out some potentially-problematic language, you can work towards being more considerate and kind to others.
alex is a lovely command-line tool that takes in text or markdown files and, using retext-equality and retext-profanities, highlights suggestions for improvement. alex checks for gendered work titles, gendered proverbs, ableist language, condescending or intolerant language, profanities, and much more.
In this short tutorial, we'll cover how to use the retext libraries alex depends on to check your Deepgram transcript utterances for suggestions.
Before You Start
Before we start, you will need a Deepgram API Key - get one here.
Create a new directory and open it in your code editor, navigate to it in your terminal, create a new package.json file by running npm init -y, and install dependencies:
npm install retext retext-equality retext-profanities vfile-reporter-json @deepgram/sdkThe retext packages require an ES6 project. The easiest way to do this without needing to compile code with a tool like Babel is to add the following property to your package.json file:
"type": "module"Create and open an index.js file in your code editor.
Generating a Transcript With Deepgram
The Deepgram Node.js is a CommonJS module, but can be imported via the default export. Because of this, our import will go from this in CommonJS:
const { Deepgram } = require('@deepgram/sdk')To this in ES6 (DG can be anything as long as it's the same in both uses):
import DG from '@deepgram/sdk'
const { Deepgram } = DGThen, generate a transcript. Here I am using a recording of my voice reading out the alex sample phrase for demonstration.
const deepgram = new Deepgram('YOUR_DEEPGRAM_API_KEY')
const url = 'http://lws.io/static/inconsiderate.mp3'
const { results } = await deepgram.transcription.preRecorded({ url }, { utterances: true })
console.log(results)As the utterances feature is being used, an array will be provided with each utterance (spoken phrase) along with when it was spoken.
Test it out! Run the file with node index.js, and you should see a payload in your terminal. Once you know it works, remove the console.log().
Setting Up the Language Checker
At the very top of index.js, include the dependencies required to set up retext and then report issues found from it:
import { reporterJson } from 'vfile-reporter-json'
import { retext } from 'retext'
import retextProfanities from 'retext-profanities'
import retextEquality from 'retext-equality'Then, create the following reusable function:
async function checkText(text) {
const file = await retext()
.use(retextProfanities)
.use(retextEquality)
.process(text)
const outcome = JSON.parse(reporterJson(file))
const warnings = outcome[0].messages.map(r => r.reason)
return warnings
}This function processes the provided text through the specified plugins (here, retextProfanities and retextEquality). The outcome is actually quite a large amount of data:
{
reason: '`man` may be insensitive, use `people`, `persons`, `folks` instead',
line: 1,
column: 9,
position: {
start: { line: 1, column: 9, offset: 8 },
end: { line: 1, column: 12, offset: 11 }
},
ruleId: 'gals-man',
source: 'retext-equality',
fatal: false,
stack: null
},The warnings map in the reusable checkText function extracts only the reason and returns an array of these strings. Try it out by temporarily adding this line:
const testSuggestions = await checkText('He is a butthead.')
console.log(testSuggestions)The result should be:
[
'Don’t use `butthead`, it’s profane',
'`He` may be insensitive, use `They`, `It` instead'
]Once you know it works, remove the console.log().
Checking Each Utterance's Language
Add the following to your index.js file below where you generate Deepgram transcripts:
let suggestions = []
for(let utterance of results.utterances) {
const { transcript, start } = utterance
// Get array of warning strings
let warnings = await checkText(transcript)
// Alter strings to be objects including the utterance transcript and start time
warnings = warnings.map(warning => ({ warning, transcript, start }))
// Append to end of array
suggestions = [...suggestions, ...warnings]
}
console.log(suggestions)Your terminal should show all of the suggestions presented by the two retext plugins:
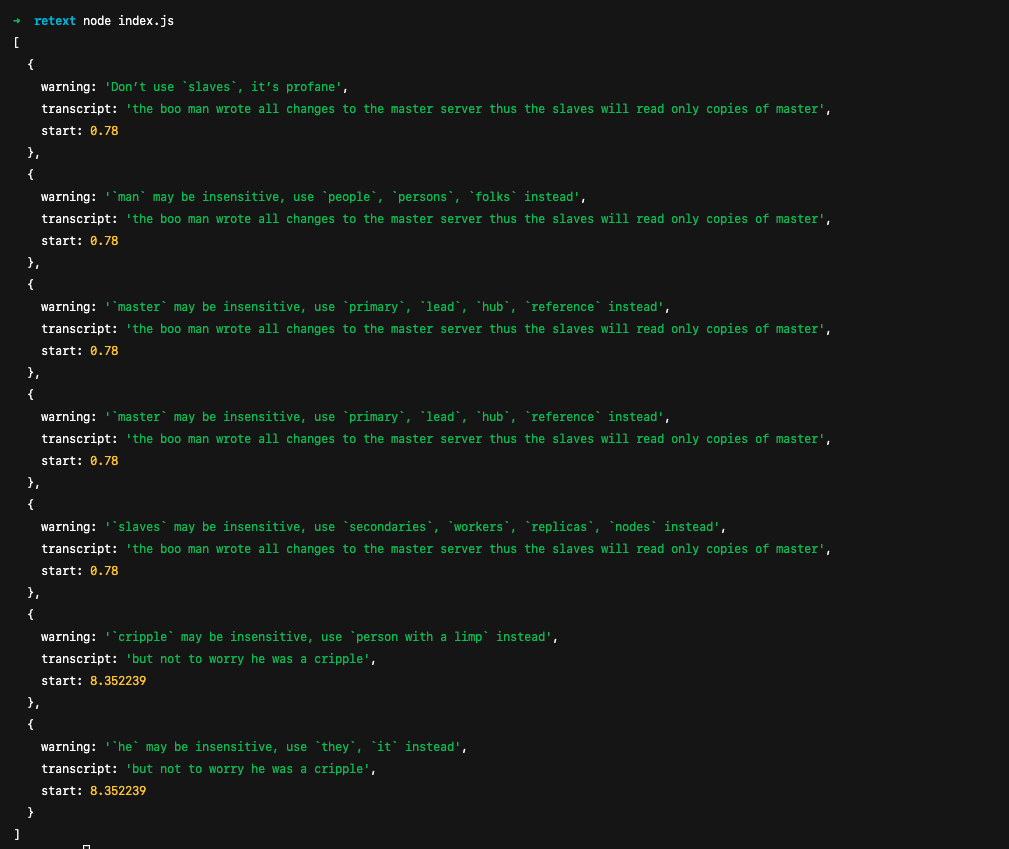
Wrapping Up
This full snippet (below) is a great place to start identifying and changing usage and non-inclusive language patterns. You may quickly realize that the retext plugins lack nuance and sometimes make suggestions on false-positive matches. Don't consider the suggestions as "must-dos", but rather points for consideration and thought.
There's a whole host of other retext plugins which you can process text with, including those that handle assumptions, cliches, passive voice, repetition, overly-complex words, and more. Enjoy!
import { reporterJson } from 'vfile-reporter-json'
import { retext } from 'retext'
import retextProfanities from 'retext-profanities'
import retextEquality from 'retext-equality'
import DG from '@deepgram/sdk'
const { Deepgram } = DG
const deepgram = new Deepgram(process.env.DG_KEY)
const url = 'http://lws.io/static/inconsiderate.mp3'
const { results } = await deepgram.transcription.preRecorded({ url }, { utterances: true })
async function checkText(text) {
const file = await retext()
.use(retextProfanities)
.use(retextEquality)
.process(text)
const outcome = JSON.parse(reporterJson(file))
const warnings = outcome[0].messages.map(r => r.reason)
return warnings
}
let suggestions = []
for(let utterance of results.utterances) {
const { transcript, start } = utterance
let warnings = await checkText(transcript)
warnings = warnings.map(warning => ({ warning, transcript, start }))
suggestions = [...suggestions, ...warnings]
}
console.log(suggestions)If you have any feedback about this post, or anything else around Deepgram, we'd love to hear from you. Please let us know in our GitHub discussions .
More with these tags:
Share your feedback
Was this article useful or interesting to you?
Thank you!
We appreciate your response.



