How to train Baidus Deepspeech model

February 21, 2017 in AI & Engineering

You want to train a Deep Neural Network for Speech Recognition?
Me too. It was two years ago and I was a particle physicist finishing a PhD at University of Michigan. I could code a little in C/C++ and Python and I knew Noah Shutty. Noah's my cofounder at Deepgram and an all around powerhouse of steep learning curve-ness. We both had no speech recognition background (at all), a little programming and applied machine learning (boosted decision trees and NN), and a lot of data juggling/system hacking experience. We found ourselves building the world's first deep learning based speech search engine. To get moving we needed a DNN that could understand speech. Here's the basic problem.
Turn this input audio ⬇⬇⬇
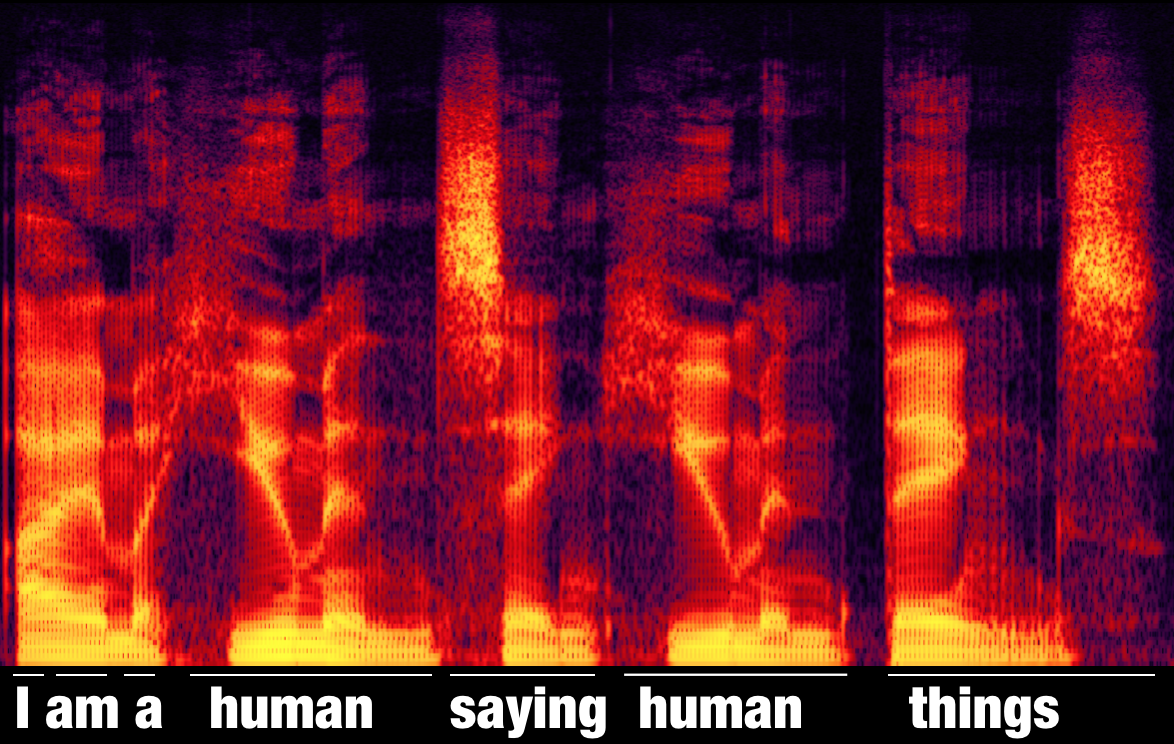 A spectrogram of an ordinary squishy human saying, "I am a human saying human things.
A spectrogram of an ordinary squishy human saying, "I am a human saying human things.
Listen to the audio.
Into this text ⬇⬇⬇
 The prediction from a DNN that just heard the "I am a human saying human things" audio file.
The prediction from a DNN that just heard the "I am a human saying human things" audio file.
Why we did it
We'll probably write a "This is Deepgram" post sometime, but suffice to say: we are building a Google for Audio and we needed a deep learning model for speech recognition to accomplish that goal. Good thing Baidu had just released the first of the Deepspeech papers two years ago when we were starting [[1]](https://arxiv.org/abs/1412.5567). This gave us the push we needed to figure out how deep learning can work for audio search. Here's a picture of the Deepspeech RNN for inspiration.

Baidu's Andrew Ng at NVidia's GTC conference talking about Deepspeech
Deep Learning is hard. There are a few reasons why that is but some obvious ones are that models and frameworks involving differentiable tensor graphs are complicated, the hardware to run them efficiently is finicky (GPUs), and it's difficult to get data. Getting a working Deepspeech model is pretty hard too, even with a paper outlining it. The first step was to build an end-to-end deep learning speech recognition system. We started working on that and based the DNN on the Baidu Deepspeech paper. After a lot of toil, we put together a genuinely good end-to-end DNN speech recognition model. We've open sourced the Deepspeech model in the Kur framework running on TensorFlow.
Quick Aside: We had to build Kur for Deepgram's survival. It's the wild west out here in A.I. and it's not possible to quickly build cutting edge models unless you have a simple way to do it.
We find that Kur lets you describe your model and then it works without having to do a lot of the plumbing that slows projects down. The Kur software package was just released. It's free. It's open source. It's named after the first mythical dragon. Kur was crafted by the whole Deepgram A.I. team and we hope it helps the deep learning community in some small way.
To get this working, download and install Kur
To install, all you really need to do is run $ pip install kur in your terminal if you have python 3.4 or above installed. If you need guidance or want easy environments to work in, we have an entire installation page at kur.deepgram.com.
Run the Deepspeech Example
Once Kur is installed, fire up your fingers and run $ kur -v train speech.yml from your kur/examples/ directory. You can omit the -v if you want Kur to quietly train without outlining what it's up to in your terminal's standard out. We find that running with -v the first few times gives you an idea of how Kur works, however. Turn on -vv if you're really craving gory details.
Your model will start training
At first, the outputs will be gibberish. But they get better :)
Hour 1:
True transcript: these vast buildings what were they
DNN prediction: he s ma tol ln wt r hett jzxzjxzjqzjqjxzq
Hour 6:
True transcript: the valkyrie kept off the coast steering to the westward
DNN prediction: the bak gerly cap dof the cost stkuarinte the west werd
Hour 24:
True transcript: it was a theatre ready made
DNN prediction: it was it theater readi made
Real English is spilling out. I trained for 48 hours in total then ran the "i am a human saying human things" audio file through the network.
Listen to the audio.
Hour 48:
True transcript: i am a human saying human things
DNN prediction: i am a human saying human things
It's just two days old and didn't make a single mistake on that utterance. Our Speech A.I. is doing pretty well.
Training and Validation Loss of Kur Deepspeech Model
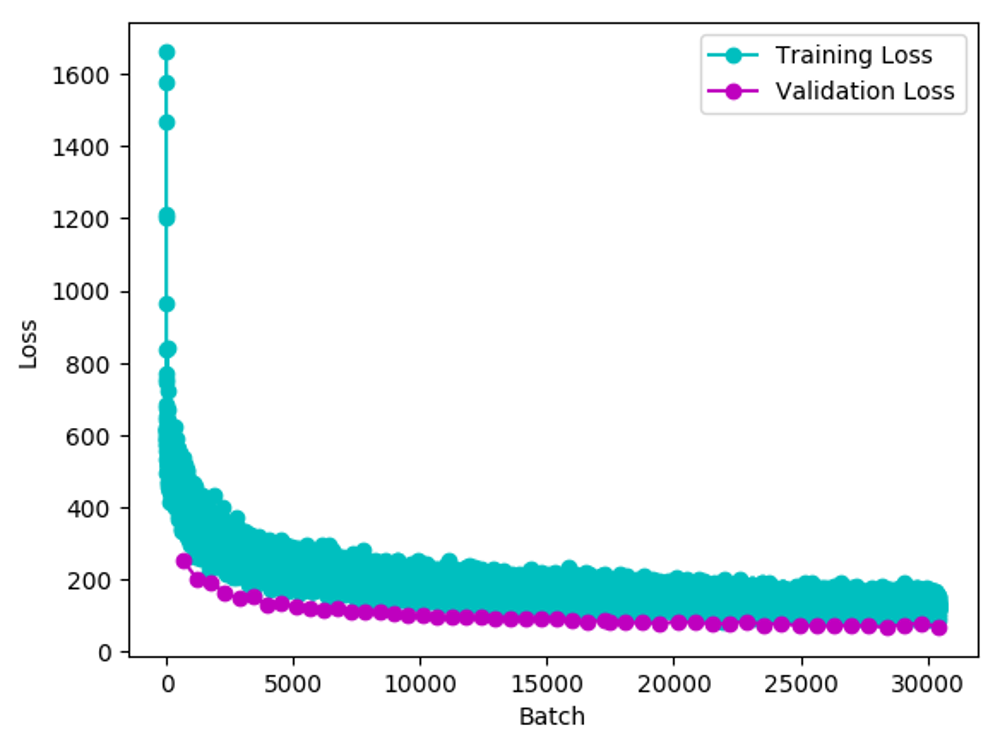
Loss as a function of batch for both training and validation data in the Kur 'speech.yml' example. The validation data seems a little easier.
There's a lot of things to try
We abstracted away some of the time consuming bits. A little help comes from the descriptive nature of Kur, too. You can write down what you mean.
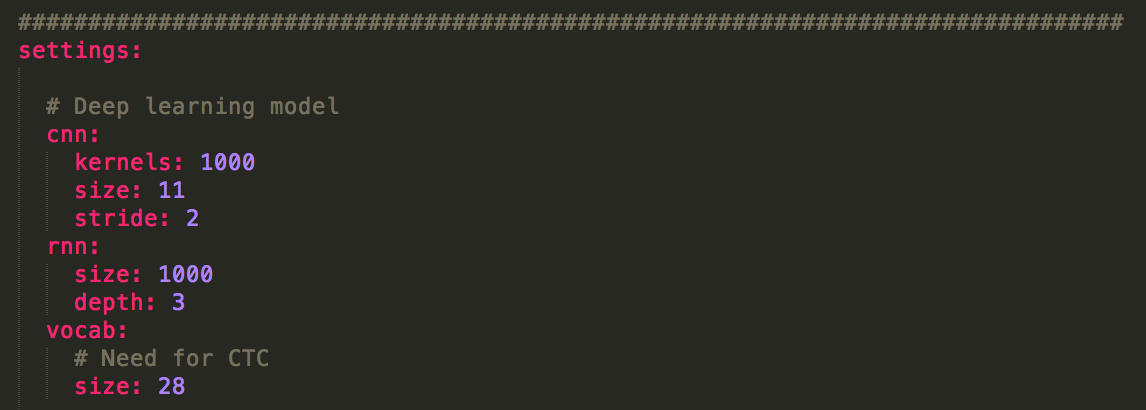 Hyperparameters for Deepspeech in the example Kurfile
Hyperparameters for Deepspeech in the example Kurfile
These are the handful of hyperparameters needed to construct the DNN. There's a single one dimensional CNN that operates on a time slice of FFT outputs. Then there's an RNN stack which is 3 layers deep and 1000 nodes wide each. The vocab size is how many 'letters' we'll be choosing from (a to z, a space and an apostrophe '-that's 28 total). The hyperparameters are grabbed in the model section of the Kurfile (that's the speech.yml). The CNN layer is built like this.
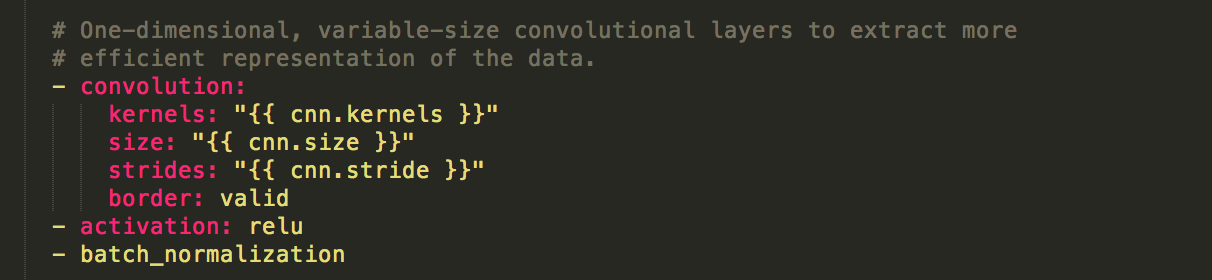 The CNN layer specification
The CNN layer specification
This puts in a single CNN layer with a few sensible hyperparameters and slaps on a Rectified Linear Unit activation layer. Note: The hyperparameters are filled in using the Jinja2 templating engine.
You can read more about defining Kurfiles in the docs at kur.deepgram.com.
The stack of RNN layers is built with a for loop that stamps out three layers in a row-three because of the depth hyperparameter.
 The RNN stack specification
The RNN stack specification
The batch normalization layer uses a technique to keep layer weights distributed in a non-crazy way, speeding up training. The rnn sequence hyperparameter just means you want the full sequence of outputs passed along (every single time slice of the audio) while generating a guess for the transcript. Quick Summary: The CNN layer ingests the FFT input then connects to RNNs and eventually to a fully connected layer which predicts from 28 letters. That's Deepspeech.
Overview of How it Works
When training modern speech DNNs you generally slice up the audio into ~20 millisecond chunks, do something like a fast fourier transform (FFT) on the chunk of audio, feed those chunked FFTs into the DNN sequentially, and generate a prediction for the current chunk. You do that until you've digested the whole file (while remembering your chunk predictions the whole way) and end up with a sequence.
This is how Deepspeech works in Kur
Kur takes in normal wav audio files. Then it grabs the spectrogram (FFT over time) of the file and jams it into a DNN with a CNN layer and a stack of three RNN layers. Out pops probabilities of latin characters, which (when read by a human) form words. As the model trains, there will be validation steps that give you an updated prediction on a random test audio file. You'll see the true text listed next to each prediction. You can watch the predicted text outputs get better as the network trains. It's learning. At first it will learn about spaces (ya know, this ), then it'll figure out good ratios for vowels and consonants, then it'll learn common easy words like the, it, a, good and build up it's vocabulary from there. It's fascinating to watch.
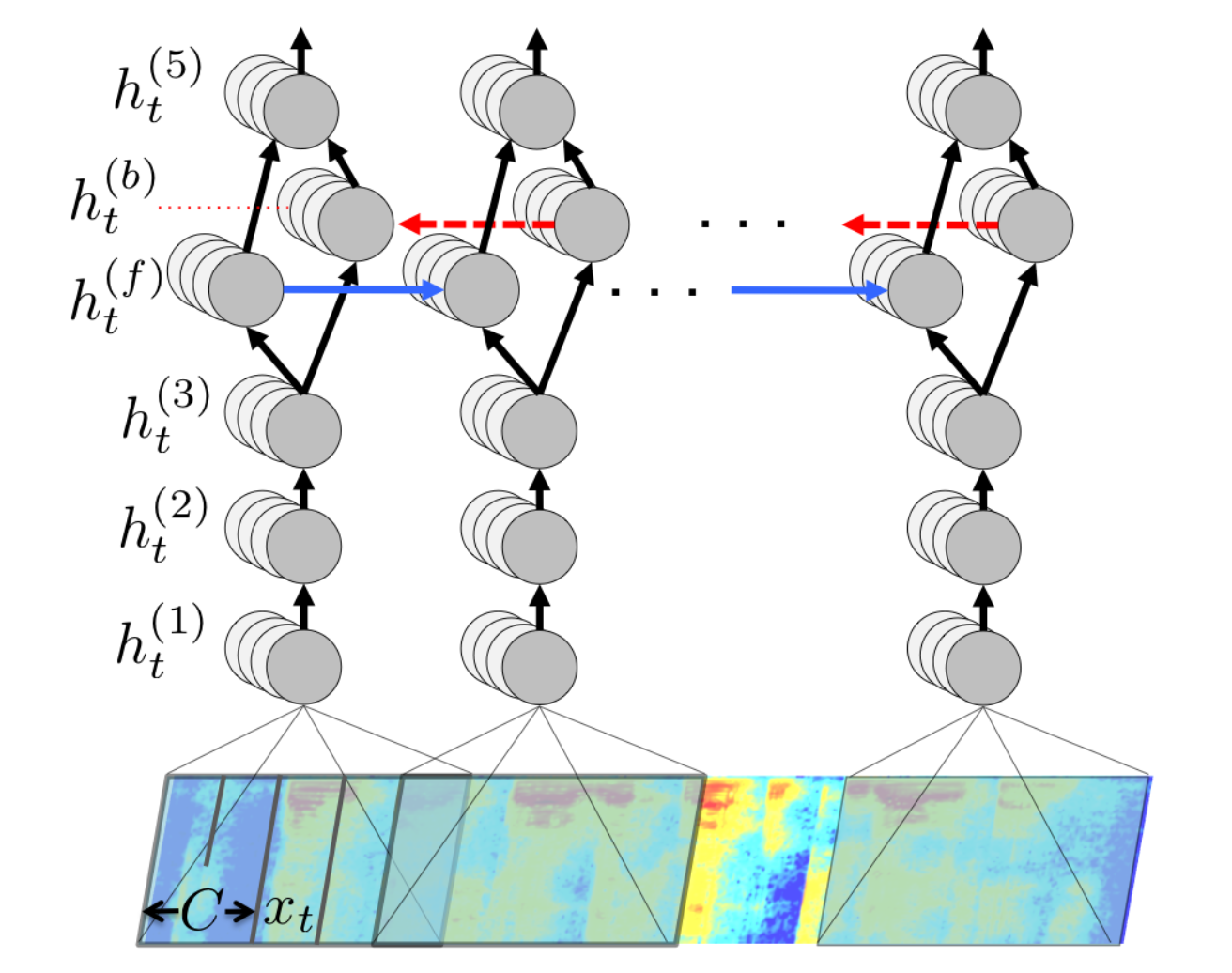
Take in time slices of audio frequencies and infer the letters that are being spoken. Time goes to the right. Image by Baidu.
Tell us what you think
At Deepgram, we're really open about what we're working on. We know that A.I. is going to be huuuge and there are not enough trained people or good tools in the world to help it along ... yet. We hope Kur, KurHub, our upcoming Deep Learning Hackathon, and blog posts like this help out the community, gets people excited, and shows that the good stuff can now be used by everyone. We're a startup and our research team can only produce so much helpful material per unit time. The best way to help us is to implement your favorite Deep Learning papers in Kur and upload it to KurHub. You can also contribute to the Kur framework directly on GitHub. You'll be showered with thanks from us and a pile of others that are hungry for good implementations.
If you have any feedback about this post, or anything else around Deepgram, we'd love to hear from you. Please let us know in our GitHub discussions .
More with these tags:
Share your feedback
Was this article useful or interesting to you?
Thank you!
We appreciate your response.



