Is There an ASR Gender Gap?

March 31, 2022 in Identity & Language

Share
In this blog post
To close out Women's History Month, we're taking a look at the intersection of women's voices and speech technology.
Gender Marking in Language
The English language has relatively little overt gender marking. Many languages-Spanish, Hebrew, Arabic, and Japanese, to name a few-have distinct word endings or vocabulary that change to reflect gender. In rarer cases, languages like Yanyuwa, an Aboriginal Australian language, develop distinct dialects for men and women. Overt gender marking in English is confined to the use of the gendered third person singular pronouns she and he. But there are other differences to be found, if you know where to look.
There are a range of speech patterns and vocal characteristics associated with women's speech in English. To be sure, the three qualities listed below are not unique to women by any stretch-but language scientists have noted that their adoption was driven by women, and to this day they tend to be associated with women's speech. Even just this short list shows that when it comes to gender, language is political. Searching the internet for uptalk and vocal fry will turn up an ocean of content decrying the "epidemic" of these speech qualities and offering advice on how to eliminate them, as though they represent a liability to the speaker. Prominent features commonly associated with female voices include:
Uptalk or upspeak: Raising the pitch of your voice toward the end of a declarative statement, which produces an intonation pattern resembling that of a question. Statements made with uptalk may be perceived as less decisive than they would be without it.
Vocal fry: Creating a creaky sound while speaking by fluttering your vocal folds at the bottom of your vocal register. Vocal fry is sometimes perceived as unsure or less confident.
Using "like" as a discourse particle or filler word: a discourse particle is a word or phrase used primarily to manage the flow of a conversation, including "you know, and "I mean." You might use "like" as a discourse particle to, like, pause and put together your next thought. Similar to vocal fry, the use of "like" as a discourse particle tends to be perceived as unsure or less confident.
Female Speech Trendsetters
Some commentators, however, see a different story: female speech shows the power that women have as language trendsetters. Mark Liberman, a linguist at the University of Pennsylvania notes, "It's generally pretty well known that if you identify a sound change in progress, then young people will be leading old people, and women tend to be maybe half a generation ahead of males on average." So, women tend to be early adopters of linguistic trends, but why do they adopt new forms of speech in the first place? Carmen Fought, a linguist at Pitzer College argues, that women's speech is a tool for social connection: "The truth is this: Young women take linguistic features and use them as power tools for building relationships."
That is to say, an uptalk pattern that signals a lack of confidence to one listener might be perceived positively by another-and it's the opportunity to build that positive connection that motivates the adoption of female speech patterns. For example, a woman might use uptalk to signal friendliness in a situation where building trust is a priority. Marybeth Seitz-Brown of Slate may have said it best when she wrote, "Young women shouldn't have to talk like men to be taken seriously." So if you hear vocal fry or uptalk and form a negative impression, it might actually be that you're missing a cue from a speaker who is ahead of you on a linguistic trend. This is one case where language is in the ear of the holder.
The conversation about women's voices goes beyond these features as well. Recent presidential races in the United States were littered with critiques of how women communicated. Sometimes it was charges of sounding "shrill" or like an "ice pick" to the ear; other times it was charges of sounding too emotional. Susan B. Anthony nodded to this issue more than a century ago, when she wrote, "No advanced step taken by women has been so bitterly contested as that of speaking in public, for nothing which they have attempted, not even to secure the suffrage, have they been so abused, condemned and antagonized."
Speech Technology and Gender
That brings us to the intersection of language and technology, where we have to ask: what role has technology played in this problem? The answer might surprise you. In the early days of voice recording, telephony, and broadcasting, decision makers in industry and government chose to limit the "voiceband" range to signals between 300 and 3,400 hertz-a range that serves the average male vocal range better than the average female vocal range.
This decision limited the intelligibility of speakers with higher vocal ranges, forcing them to modify their speech to be better understood and leading to a less natural sound (think of the critiques of women's voices as "shrill"). Despite a century of technological advances, analysis from the New Yorker reported that, "Even today, many data-compression algorithms and bluetooth speakers disproportionately affect high frequencies and consonants, and women's voices lose definition, sounding thin and tinny." In short, it will take conscious effort throughout the tech world to identify and address shortcomings in processing women's speech.
ASR Gender Gap
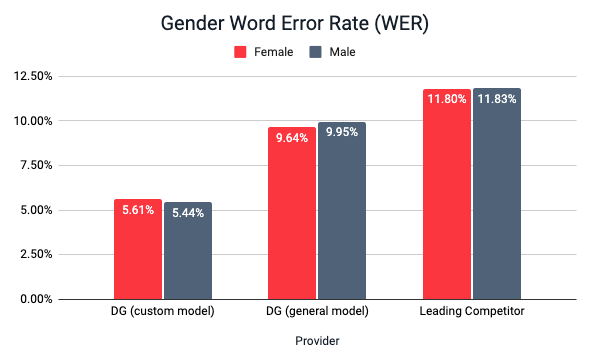
We took a look at Automatic Speech Recognition (ASR) data from ourselves and our competitors to see what evidence there is of a gender gap in ASR. For this study, we compiled 1000 short audio files from an open speech dataset, totaling just under 4 hours of audio. 500 of the files were female speakers, 500 were male. We set aside a small validation set and then ran the rest of these audio files through three models: the Deepgram general model, a Deepgram-trained model, and the model of a leading competitor.
The results show that in terms of overall performance, Deepgram's trained model had the best performance at ~5.5% WER, followed by Deepgram's general model at ~9.8%, and then the leading competitor's model at ~11.8%. Overall, the data shows that the accuracy gap between male and female speakers is very small. This is an encouraging sign given the historical legacy of women's voices not being prioritized in tech.
We're in the business of making human speech intelligible to machines because we know there's power in voice. Equality in speech technology will be a precondition for getting your voice out into the world. At Deepgram, our Research team tracks our ability to process speech of different demographic groups, including women, and aims for continuous improvement.
If you have any feedback about this post, or anything else around Deepgram, we'd love to hear from you. Please let us know in our GitHub discussions .
More with these tags:
Share your feedback
Was this article useful or interesting to you?
Thank you!
We appreciate your response.



