Multichannel vs Diarization

December 20, 2021 in Best Practices

We sometimes get questions from developers about Deepgram's multichannel and diarize features. In this post, I will provide some examples of when each feature might come in handy, and I'll try to provide a little more clarity on what each feature does.
Multichannel
Introduction to Multichannel Audio
You may have heard of stereo sound, which is sound produced from two different audio channels, one for left and one for right. When you listen to sound in stereo, it comes across as sounding wider and as having more depth. Stereo sound was a great improvement upon mono sound, which sounded much more shallow. Multichannel audio can be stereo (two channels) or even more than two channels.
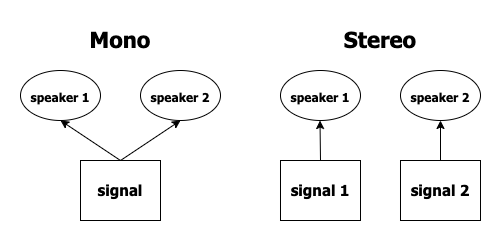
When recording people speaking, multichannel can be used to separate different people's voices into individual channels, for example, on a call between a customer and salesperson, or doctor and patient, and so on. This would make it much easier to focus on one speaker when reviewing the audio file, which is why many companies that have a need to review audio conversations and transcripts choose to use multichannel audio for their recordings.
While two-speaker, two-channel is most common, there could be situations where one channel has several voices. Perhaps a podcast has two interviewers on one channel and one interviewee on a second channel.
The point is, multichannel audio divides audio into separate channels, and the audio on those separate channels is distinct.
Deepgram's Multichannel Feature
By setting multichannel=true in a query parameter via the API or an SDK, you are telling Deepgram to transcribe each audio channel independently. If you print response.results.channels to the console, you will see a response that comes back as separate channels for each channel from the audio.
Here is an example response for an audio file that has two separate channels:
"channels": [
{
alternatives: [
{
transcript: "parker scarves how may i help you",
confidence: ...,
words: ...
}
]
},
{
alternatives: [
{
transcript: "i got a scarf online for my wife",
confidence: ...,
words: ...
}
]
}
]Multichannel Joint Audio
If you have an audio file that you think is multichannel and you expect it to return two or more Deepgram transcripts that are different, but you get a response that shows the separate channels with transcripts that are the same, you may be dealing with a special situation of a joint stereo audio file.
Sometimes, in order to save file space when creating or converting an audio file, multichannel audio will undergo a process that mixes the channels into one main channel. Deepgram will still identify that there are two channels, but the transcript itself will be identical (so if there are two speakers, their speaking parts will be combined as one transcript). Here is an example:
"channels": [
{
alternatives: [
{
transcript:
'parker scarves how may i help you i got a scarf online for my wife',
confidence: 0.9453125,
words: [Array],
},
],
},
{
alternatives: [
{
transcript:
'parker scarves how may i help you i got a scarf online for my wife',
confidence: 0.9453125,
words: [Array],
},
],
},
]In this situation, it might be useful to use the diarization feature instead of the multichannel feature. In the next section, it should become clear to you why.
Diarization
Diarization in Automatic Speech Recognition
"Diarization" is a term known to people who work in ASR, but it might be new to you. Wikipedia describes diarization as "the process of partitioning an input audio stream into homogeneous segments according to the speaker identity." This just means that diarization separates audio by the person speaking, whether they are on a different channel or not.
Based on that description, you can probably see how multichannel and diarization might have some overlap. However, diarization focuses on giving information about different speakers, while multichannel focuses on identifying different audio channels.
Deepgram's Diarization Feature
By setting diarize=true in a query parameter via the API or an SDK, you are telling Deepgram that you want to know which word in the transcript was spoken by a unique human speaker. If there are two speakers in the conversation, as in the following example, you will see speaker: 0 and speaker: 1 to identify the two different people who are talking in the audio file.
Notice that the transcript is combined. Deepgram's diarization feature does not divide the transcripts into separate transcripts by speaker; it provides a speaker property for each word.
[
{
alternatives: [
{
transcript: "parker scarves how may i help you i got a scarf online for my wife",
confidence: 0.94873047,
words: [
{
word: 'parker',
start: 1.1770647,
end: 1.4563681,
confidence: 0.7792969,
speaker: 0
},
{
word: 'scarves',
start: 1.6558706,
end: 1.8553731,
confidence: 0.5029297,
speaker: 0
},
{
word: 'how',
start: 2.0548756,
end: 2.174577,
confidence: 0.99902344,
speaker: 0
},
{
word: 'may',
start: 2.174577,
end: 2.254378,
confidence: 0.9995117,
speaker: 0
},
{
word: 'i',
start: 2.3341792,
end: 2.4538805,
confidence: 0.9980469,
speaker: 0
},
{
word: 'help',
start: 2.4538805,
end: 2.733184,
confidence: 1,
speaker: 0
},
{
word: 'you',
start: 2.733184,
end: 2.892786,
confidence: 0.9838867,
speaker: 0
},
{
word: 'i',
start: 4.089801,
end: 4.209502,
confidence: 0.54589844,
speaker: 1
},
{
word: 'got',
start: 4.209502,
end: 4.329204,
confidence: 0.6279297,
speaker: 1
},
{
word: 'a',
start: 4.329204,
end: 4.6883082,
confidence: 0.9580078,
speaker: 1
},
{
word: 'scarf',
start: 4.6883082,
end: 5.1883082,
confidence: 0.9760742,
speaker: 1
},
{
word: 'online',
start: 5.2469153,
end: 5.526219,
confidence: 0.6933594,
speaker: 1
},
{
word: 'for',
start: 5.526219,
end: 5.6459203,
confidence: 0.7602539,
speaker: 1
},
{
word: 'my',
start: 5.6459203,
end: 5.8454227,
confidence: 0.98876953,
speaker: 1
},
{
word: 'wife',
start: 5.8454227,
end: 6.044925,
confidence: 0.7709961,
speaker: 1
},Combining Deepgram's Multichannel with Diarization
If you are thinking of combining the multichannel and diarization features, it is helpful to really understand how these features work, especially when you are trying to get information about speakers.
For example, in a transcript that has two different human speakers, each of them on different audio channels, adding multichannel=true and diarize=true to the query will return the two separate transcripts for each channel, but the speaker property will return speaker: 0 for both human speakers. This is because there is only one speaker on each distinct audio channel, so each of those human speakers gets assigned as the one speaker, speaker: 0.
However, in some cases, it might be useful to you to use the diarize feature with the multichannel feature. If there are several speakers on one audio channel and several speakers on another audio channel, turning on the diarize feature might come in handy if you want to identify different speakers who are speaking on each separate channel.
Here are some situations to get you thinking about this. In the following scenarios, would it be useful to use multichannel or diarize (or both)?
Scenario: Two audio channels with the same human speaker on each channel
The first scenario is a person doing a sound check to see that sound is coming from two different inputs:
transcript: "hello and welcome to the sound test we're starting from the left channel then follows right channel left channel right channel left channel right channel and once again let channel know alright thank you so much listening to me and have a nice day"Because there is only one person talking, but that person is using two different audio input channels, using multichannel=true could be useful so that we break up the transcript by separate audio channels:
"channels": [
{
alternatives: [
{
transcript: "hello and welcome to sound test we're starting from the left channel and follows left channel left channel and once again let channel know thank you so much for listening to me and have a nice day",
confidence: 0.9472656,
words: [Array]
}
]
},
{
alternatives: [
{
transcript: "hello and welcome to the sound test we're starting from there then follows right channel right channel right channel and once again right channel thank you so much and have a nice day",
confidence: 0.9326172,
words: [Array]
}
]
}
]The diarize feature would not be as helpful since it is the same human speaker on both of the input channels.
Scenario: Two audio channels with two human speakers (one human speaker on each channel)
;[
{
alternatives: [
{
transcript:
"thank you for calling marcus flowers hello i'd like to order flowers and i think you have what i'm looking for i'd be happy to take care of your order may i have your name please",
confidence: 0.9814453,
words: [Array],
},
],
},
]Again, it would be useful to use multichannel to separate the audio channels since there is an individual human speaker on each channel. And since there is only one human speaker on each channel, using diarize might not be as useful to us since both speakers will be assigned the same value, as speaker: 0. Using multichannel gives us:
[
{
alternatives: [
{
transcript: "thank you for calling marcus flowers i'd be happy to take care of your order may i have your name please",
confidence: 0.9819336,
words: [{
word: 'thank',
start: 0.94,
end: 1.06,
confidence: 0.99658203,
speaker: 0
},
...
]
}
]
},
{
alternatives: [
{
transcript: "hello i'd like to order flowers and i think you have what i'm looking for",
confidence: 0.9916992,
words: [{
word: 'hello',
start: 4.0095854,
end: 4.049482,
confidence: 0.9897461,
speaker: 0
},
...
]
}
]
}
]Scenario: One audio channel with two speakers
In cases when you just have one audio channel, the Deepgram multichannel feature probably doesn't provide you with the information you are looking for. But in this scenario, diarize could give you some useful information to help you identify the two different human speakers.
I also recommend analyzing the start and end property in combination with the speaker data if you want to find sections of audio where people might be talking over each other, which is something that is very common in transcriptions of natural conversations and discussions.
[
{
alternatives: [
{
transcript: "from npr news this is all things considered i'm robert siegel and i'm michelle norris",
confidence: 0.9794922,
words: [
{
word: 'from',
start: 0.81824785,
end: 0.8980769,
confidence: 0.99658203,
speaker: 0
},
{
word: 'npr',
start: 1.2573076,
end: 1.3770512,
confidence: 0.95947266,
speaker: 0
},
{
word: 'news',
start: 1.4967948,
end: 1.736282,
confidence: 0.99609375,
speaker: 0
},
{
word: 'this',
start: 1.9358547,
end: 2.0555983,
confidence: 0.9897461,
speaker: 0
},
{
word: 'is',
start: 2.0555983,
end: 2.2152565,
confidence: 0.9814453,
speaker: 0
},
{
word: 'all',
start: 2.2152565,
end: 2.414829,
confidence: 0.9902344,
speaker: 0
},
{
word: 'things',
start: 2.414829,
end: 2.853889,
confidence: 0.9941406,
speaker: 0
},
{
word: 'considered',
start: 2.853889,
end: 3.2929487,
confidence: 0.9785156,
speaker: 0
},
{
word: "i'm",
start: 3.452607,
end: 3.532436,
confidence: 0.9863281,
speaker: 0
},
{
word: 'robert',
start: 3.6521795,
end: 3.8916667,
confidence: 0.98876953,
speaker: 0
},
{
word: 'siegel',
start: 4.01141,
end: 4.210983,
confidence: 0.49243164,
speaker: 0
},
{
word: 'and',
start: 4.370641,
end: 4.45047,
confidence: 0.9794922,
speaker: 1
},
{
word: "i'm",
start: 4.570214,
end: 5.049188,
confidence: 0.4260254,
speaker: 1
},
{
word: 'michelle',
start: 5.049188,
end: 5.208846,
confidence: 0.69384766,
speaker: 1
},
{
word: 'norris',
start: 5.32859,
end: 5.82859,
confidence: 0.9379883,
speaker: 1
},Scenario: Two channels four speakers, three on one channel, one on the other channel
For this scenario (which I'm not going to include an example of due to the difficulty reading the long response), you could benefit from using both features. The multichannel feature would separate the transcripts by the audio input channels, and the diarize feature would help you identify the three different human speakers on the first channel.
Conclusion
I hope this helped to clarify how Deepgram's multichannel feature and diarize feature can be used to your advantage. Feel free to reach out to me on Twitter with any questions!
If you have any feedback about this post, or anything else around Deepgram, we'd love to hear from you. Please let us know in our GitHub discussions .
More with these tags:
Share your feedback
Was this article useful or interesting to you?
Thank you!
We appreciate your response.



