How to Build the World's Ugliest Podcast Search Engine with Python

August 26, 2022 in Tutorials

Simone Giertz has a great TED Talk where she extols the virtues of building useless things. I often find myself building useless things to teach others about new technologies and development practices. So when I started picking up Python, building another useless thing seemed like the best way to start.
Since Python is an object-oriented language, I expected to pick it up quickly. After decades of .NET and JavaScript, OOP languages are my safe space. But beyond the syntax, what type of things do I need to know? I made a list:
Loops and conditions
File access
HTTP requests
Then there were questions like "could I build an API?" and "what do Python developers do for front-ends?" Of course, Deepgram has a Python SDK so gaining experience using it would be beneficial and I could even provide feedback to the folks that are building it. That meant I needed to do something with audio. HTTP requests, audio, files, loops, and conditions... clearly, I needed to build a search engine for podcasts.
Since I'm still learning Python, I leaned on our team at Deepgram to help me speed up the process. First up, accessing a podcast's RSS feed and identifying the URL to the mp3 files.
Pulling Podcast Episodes from an RSS Feed
Neil deGrasse Tyson has a great podcast called StarTalk Radio that would provide tons of searchable words. Its RSS feed is located at https://feeds.simplecast.com/4T39_jAj, so I needed to read that and pull in individual episodes. Originally, I planned to save the data from the feed into a PostgreSQL or MySQL database but decided to keep it simple by just saving the info from one episode to a Python file.
I created a file named load.py to get the episode information and transcribe
the audio. You can see the code below, but the TL;DR is that it:
Downloads the RSS feed locally to a file called
theRSSfeed.xmlParses the XML in that file to find all the mp3 URLs
Takes the first episode and feed its mp3 to Deepgram for transcription
Saves the transcript that Deepgram generates to a file named
podcast_data.py
# use python3
import requests
from os.path import exists
import xml.etree.ElementTree as ET
from urllib.parse import scheme_chars, urlparse, parse_qs
import json
# testing to see if we already downloaded an xml file
# if not, download it and save to file
the_rss_file = "theRSSfeed.xml"
file_exists = False
file_exists = exists(the_rss_file)
if not file_exists:
print("no file found:", the_rss_file, "... downloading ...")
url = "https://feeds.simplecast.com/4T39_jAj" # startalk podcast rss feed
response = requests.get(url)
the_content = response.content
with open(the_rss_file, "wb") as outfile:
outfile.write(the_content)
else:
print("found file:", the_rss_file, "... using it ...")
with open(the_rss_file, "rb") as infile:
the_content = infile.read()
# grab the tree object from the parsed xml file
root = ET.fromstring(the_content)
# loop through it and find all mp3s in the document
# (the way I found which query to make [the "enclosure" query])
# is by using my eyeballs to find the relevant location of mp3s
# in the rss feed, other rss feeds might be different
list_of_mp3s = []
for thing in root.iter('enclosure'):
full_url_mp3 = thing.attrib["url"]
parsed_url = urlparse(full_url_mp3) # stripping off query params
the_mp3_url = parsed_url.scheme + "://" + parsed_url.hostname + parsed_url.path
list_of_mp3s.append(the_mp3_url)
first_mp3 = list_of_mp3s[:1][0] # take the first
# now feed this url to DGs transcription API. You would keep track of the
# transcription object you get back so you can use it later for
# searching capabilities.
DG_API_KEY = "YOUR_DEEPGRAM_API_KEY_HERE"
headers = {
'content-type': "application/json",
'Authorization': "Token " + DG_API_KEY
}
response = requests.post(
"https://api.deepgram.com/v1/listen?punctuate=true&utterances=true", headers=headers, json={"url": first_mp3})
print(first_mp3)
open('/workspace/podcast_data.py',
'wb').write(response.content)Then I ran python load.py and BAM!, I've got a podcast_data.py with the
transcript of the episode. Now to start building an API that I can send search
terms to.
Building the Podcast Search Engine
I spent some time reading Tonya's blog posts on FastAPI and Django, but eventually decided on Flask to build the back-end API.
Receiving and Responding to Requests
Before I could receive search terms and respond, I had to figure out how to receive any request and return a response. Luckily, the Flask documentation provides several good examples of doing that. I started by installing Flask with pip.
pip install FlaskFlask's documentation told me that if I name my file app.py I can default to
starting the server using flask run in the terminal. I started with a very
basic app.py to see if I could return anything.
from flask import Flask
app = Flask(__name__)
@app.get("/")
def index():
return {
"name": "Hello World"
}
That little bit of Python returns a JSON object. Visiting http://127.0.0.1:5000,
confirmed that it responded with the JSON I expected. Now I can receive a
request and respond to it.
Next, I needed to be able to receive data that is sent via an HTTP POST request.
Again, I was saved by the Flask documentation. I knew that I would eventually be
sending a form field named search, so I added a new method to the app.py
file:
@app.post("/")
def index_post():
search = request.form['search']
return {
"name": "You searched for " + search
}Note on the above: It also requires you to modify the
from flask import Flasktofrom flask import Flask, request.
A quick test confirmed that I could pass in form values and respond with them. With those wins under my belt, I was ready to tackle the job of searching through the transcript.
Searching the Podcast Transcript
To make sure I'm comparing apples to apples, I needed some basic text
normalization. The text_normalize function lowercases everything, removes
common punctuation, removes unnecessary whitespace, and flattens the string to
ASCII.
def deep_replace(inString, inQuery, inReplacement):
text = inString
query = inQuery
replacement = inReplacement
text = text.replace(query, replacement)
if query in text:
return deep_replace(text, query, replacement)
else:
return text
def text_normalize(inString):
text = inString
text = normalize('NFKD', text).encode(
'ascii', 'ignore').decode('ascii').lower()
text = deep_replace(text, "?", " ")
text = deep_replace(text, ".", " ")
text = deep_replace(text, "!", " ")
text = deep_replace(text, ",", " ")
text = deep_replace(text, "-", " ")
text = " ".join(text.split())
return textOnce I knew I could compare strings relatively well, it was time to look through
the transcript to find a search phrase. All the magic of the search engine takes
place in the search function. First, it normalizes the phrase I'm searching
for and then looks through all the words in the transcript for a match.
For any matches, it creates a string containing the matching word and the five
words that precede and follow the matching word. The match and its corresponding
phrase are loaded to an array called query_results that is finally returned.
def search(phrase):
the_query = phrase
the_query = text_normalize(the_query)
print(the_query)
# word array search
the_body_array = podcast_data.data["results"]["channels"][0]["alternatives"][0]["words"]
the_body_list = []
for thing in the_body_array:
the_body_list.append(text_normalize(thing["word"]))
query_index_list = [idx for idx, s in enumerate(
the_body_list) if the_query in s]
query_results = []
for i in query_index_list:
backforwardcount = 5
quick_text = " ".join(the_body_list[max(
0, i-backforwardcount):min(i+backforwardcount, len(the_body_list))])
query_results.append([the_body_array[i], quick_text])
return query_resultsWith the search function ready, it was time to update the POST route of my API.
I passed the search phrase submitted in the POST request to my search function
and then returned the result.
@app.post("/")
def index_post():
phrase = request.form['search']
query_results = search(phrase=phrase)
return query_resultsJust like magic, I could send requests to my API and have it return matches in the podcast. But no one wants to send cURL requests all day. It was time to build the worst user interface for a search engine ever.
Building the Ugliest User Interface
The last step was to build a user interface. Fortunately, since I was building the ugliest search engine, the bar was low on how it looked. In fact, it was a bit of a challenge to not try and improve the interface. 😁
The Search Interface
One of the reasons I chose to use Flask on the back-end was the fact that it supported Jinja2 out of the box. I had never used Jinja2, but when someone mentioned it in our Slack, I noticed how similar it was to Handlebars for JavaScript developers.
My goal was to create one HTML file that could display the search box and
results. To separate it from my Python code, I created a new HTML file
at templates/index.html. It was very basic with an H1 tag and a form that
would send a post back to its route.
<html>
<head>
<title>Podcast Search</title>
</head>
<body style="text-align:center;">
<h1>World's Ugliest Podcast Search</h1>
<form action='#' method='POST'>
<label for='search'>Search for a word</label><br />
<input type='text' name='search' value='{{ search }}' /><br />
<button type="submit">Search</button>
</form>
</body>
</html>Once the HTML file was in place, I updated the original HTTP GET request to
serve it. Because I'm injecting the search parameter, I needed to supply it
with an empty string.
@app.get("/")
def index():
return render_template('index.html', search="")A quick flask run in the terminal served up my ugly podcast search engine. To
my surprise, it was technically already working. When I entered a search phrase
and pressed the 'Search' button, it sent the search phrase to the API, which
returned the results as JSON. Of course, that's not what I want it to do in the
end, but it was a great feeling to know I was close to the end.
Displaying the Search Results
While a JSON response would be pretty ugly, I was enjoying Jinja2 too much to
not build an interface to display the results of the search. After the form in
my templates/index.html file, I added an H2 and UL to list the results. If
there was a search phrase, it shows any results in a list.
{% if search %}
<h2>Search results for {{ search }}</h2>
<ul style="list-style: none;">
{% for result in results %}
<li style="padding:1rem;">
{{ result[1] }}
</li>
{% endfor %}
</ul>
{% endif %}Once the template was ready, I needed to update my API to return the HTML.
Rather than returning the results as JSON, I return render_template passing
the search phrase and the query results.
@app.post("/")
def index_post():
phrase = request.form['search']
query_results = search(phrase=phrase)
return render_template('index.html', search=phrase, results=query_results)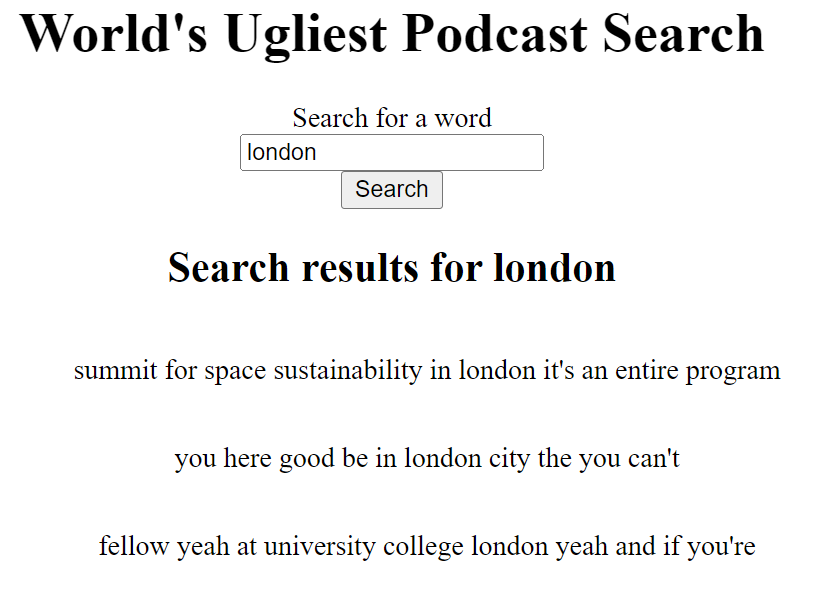
There you have it. Searching works and shows all places where a word was spoken. The phrases are a nice touch because they give context to what is being said at that moment. That should be the end right? Oh no. I'm nothing if not a little extra. It was time to add a little pizzazz.
Getting a Little Fancy
We're searching through podcasts. By their nature, they are meant for audio. While I could have stopped by showing the phrase the user was looking for, I thought it would be cooler if we could play that section of audio. I started by adding an audio player to the HTML file with the podcast episode I'm searching through. Users can press play and listen to the podcast if they like, but the real fun will happen once they search.
<audio controls>
<source
src="https://stitcher.simplecastaudio.com/8b62332a-56b8-4d25-b175-1e588b078323/episodes/774634ab-c3f5-4100-b6a0-8554c63002c0/audio/128/default.mp3"
type="audio/mpeg">
Your browser does not support the audio element.
</audio>Next, I updated the result LI elements to include an anchor tag that will call
a JavaScript function. (You know I wouldn't get through all this work without
using a touch of JavaScript.) When it calls the upcoming seek function, it
supplies it with the timestamp of the start of the found word.
<a href="javascript:void(0);" onclick="seek({{result[0].start}})">{{ result[1] }}</a>Finally, I added a JavaScript function to the head of the page called seek. It
expects a timestamp parameter. It then grabs the audio player, pauses its
playback, seeks to timestamp location minus eight-tenths of a second, and plays.
Why eight-tenths? I found it started the audio a few words before the searched
phrase so you can better hear the word in context.
<script type="text/javascript">
function seek(timestamp) {
const audio = document.getElementsByTagName('audio')[0];
audio.pause();
audio.currentTime = timestamp - .8;
audio.play();
}
</script>
Final Results
Overall, I really enjoyed dipping my toes into the Python world. I learned several things that are universal to all languages and I'm excited to learn more. If you want to build this fun, but completely useless project, the full Python and HTML files are below. Enjoy!
# app.py
from flask import Flask, render_template, request
from unicodedata import normalize
import podcast_data
app = Flask(__name__)
@app.get("/")
def index():
return render_template('index.html', search="")
@app.post("/")
def index_post():
phrase = request.form['search']
query_results = search(phrase=phrase)
return render_template('index.html', search=phrase, results=query_results)
def search(phrase):
the_query = phrase
the_query = text_normalize(the_query)
the_body_array = podcast_data.data["results"]["channels"][0]["alternatives"][0]["words"]
the_body_list = []
for thing in the_body_array:
the_body_list.append(text_normalize(thing["word"]))
query_index_list = [idx for idx, s in enumerate(
the_body_list) if the_query in s]
query_results = []
for i in query_index_list:
backforwardcount = 5
quick_text = " ".join(the_body_list[max(
0, i-backforwardcount):min(i+backforwardcount, len(the_body_list))])
query_results.append([the_body_array[i], quick_text])
return query_results
def deep_replace(inString, inQuery, inReplacement):
text = inString
query = inQuery
replacement = inReplacement
text = text.replace(query, replacement)
if query in text:
return deep_replace(text, query, replacement)
else:
return text
def text_normalize(inString):
text = inString
text = normalize('NFKD', text).encode(
'ascii', 'ignore').decode('ascii').lower()
text = deep_replace(text, "?", " ")
text = deep_replace(text, ".", " ")
text = deep_replace(text, "!", " ")
text = deep_replace(text, ",", " ")
text = deep_replace(text, "-", " ")
text = " ".join(text.split())
return text<!-- templates/index.html -->
<html>
<head>
<title>Podcast Search</title>
<script type="text/javascript">
function seek(timestamp) {
const audio = document.getElementsByTagName('audio')[0];
audio.pause();
audio.currentTime = timestamp - .8;
audio.play();
}
</script>
</head>
<body style="text-align:center;">
<h1>World's Ugliest Podcast Search</h1>
<form action='#' method='POST'>
<label for='search'>Search for a word</label><br />
<input type='text' name='search' value='{{ search }}' /><br />
<button type="submit">Search</button>
</form>
<audio controls>
<source
src="https://stitcher.simplecastaudio.com/8b62332a-56b8-4d25-b175-1e588b078323/episodes/774634ab-c3f5-4100-b6a0-8554c63002c0/audio/128/default.mp3"
type="audio/mpeg">
Your browser does not support the audio element.
</audio>
{% if search %}
<h2>Search results for {{ search }}</h2>
<ul style="list-style: none;">
{% for result in results %}
<li style="padding:1rem;">
<a href="javascript:void(0);" onclick="seek({{result[0].start}})">{{ result[1] }}</a>
</li>
{% endfor %}
</ul>
{% endif %}
</body>
</html>If you have any feedback about this post, or anything else around Deepgram, we'd love to hear from you. Please let us know in our GitHub discussions .
More with these tags:
Share your feedback
Was this article useful or interesting to you?
Thank you!
We appreciate your response.



