

Imagine having the ability to monitor certain words or phrases during phone conversations by doing voice transcription with Python. This capability is a typical use case for a call center where calls are monitored between a customer service agent and a customer. Most of these conversations start with the agent saying, “This call is recorded for quality assurance purposes”. This phrase is usually legally required to inform the person on the other end that they are being recorded, and this scenario is a common use case for ASR technology known as script compliance.
Combining voice transcription with Python using Deepgram, there are many innovative ways to monitor script compliance without manually listening to each recorded call. Deepgram provides a speech-to-text solution that transcribes audio to text with Python, real-time and pre-recorded calls. This solution is ideal to:
Provide insights into how the agent handled the call by running analytics in Python (you can read more about analytics with Deepgram and Python here.
Keep customers happy by improving their experience and satisfaction, increasing sales and revenue.
Reduce costs and save time by identifying non-compliance immediately.
In the next section, let’s review the project we’ll build together. If you’d like to jump ahead and grab the code for this project, you can do so here in our Github repo.
What We’ll Build
This tutorial will use the Deepgram Python SDK to build a simple script that transcribes audio to text with Python and simulates monitoring script compliance by searching words and phrases. Although Deepgram has a diarize feature to help us recognize speakers when multiple people are talking (which is very useful for script compliance examples with an agent and a customer), we’ll use a script with one person speaking to keep things simple. In a previous article we built a project using the diarize feature to gather transcripts for multiple speakers if you'd like to learn more.
We’ll focus on monitoring script compliance by doing the following:
Read our audio and receive our transcript
Write a function that searches for flagged words and phrases
Use the same function to search for wanted keywords and phrases
Create a scorecard of how many flagged words and keywords are spoken
Now that we’re clear on what we’re building let’s get started!
Getting Started
Before we start, it’s essential to generate a Deepgram API key to use in our project. We can go to our Deepgram console. Make sure to copy it and keep it in a safe place, as you won’t be able to retrieve it again and will have to create a new one. In this tutorial, we’ll use Python 3.10, but Deepgram supports some earlier versions of Python.
Next, let’s make a directory anywhere we’d like.
mkdir deepgram_script_complianceThen change into that directory so we can start adding things to it.
cd deepgram_script_complianceWe’ll also need to set up a virtual environment to hold our project and its dependencies. We can read more about those here and how to create one.
It’s recommended in Python to use a virtual environment so our project can be installed inside a container rather than installing it system-wide.
Now we can open up our favorite editor and create a file called script_compliance.py. If you’d like to make it from the command line, do this:
touch script_compliance.pyFinally, let’s install our dependencies for our project. Ensure our virtual environment is activated because we’ll install those dependencies inside. If your virtual environment is named venv, then activate it.
source venv/bin/activateAfter activation, we install the dependencies, including:
The Deepgram Python SDK
The dotenv library helps us work with our environment variables
The library Tabulate to pretty-print our tables
The Colorama library to color-code our terminal
<!---->
pip install deepgram-sdk
pip install python-dotenv
pip install tabulate
pip install coloramaThe following section will show the ease of using Python with Deepgram to monitor search terms with a newbie-friendly script.
The Code
Let’s open our script_compliance.py file and include the following code at the top:
import asyncio
from deepgram import Deepgram
from dotenv import load_dotenv
from typing import Dict
from tabulate import tabulate
from colorama import init
from colorama import Fore
import os
init()
load_dotenv()
PATH_TO_FILE = 'gettysburg.wav'
flagged_words = {
"and": "This is a flagged word!",
"are": "This is another flagged word!",
"um": "This is a filler word!"
}
search_words = ["engaged in a great civil war", "new nation", "Ok I see"]
score_card = []The first part is Python imports. We need to access the modules and libraries for our script to work correctly.
The load_dotenv() will help us load our api_key from an env file, which holds our environment variables.
The PATH_TO_FILE = 'gettysburg.wav' is a path to the audio file we’ll use to do the speech-to-text transcription.
The flagged_words dictionary is where we’ll keep the words in a key which we monitor what we don’t want our speaker to say. The values in the dictionary contain a warning for each flagged word.
The search_words list are words or phrases that we monitor and want our speaker to say during the audio.
The score_card will keep track of how many flagged words and search words our speaker says in the transcript.
Create an env file at the same level as our script_compliance.py. Put the following inside of it:
DEEPGRAM_API_KEY = “YOUR_API_KEY”We replace YOUR_API_KEY with our api_key, which we got from Deepgram.
Next, let’s add the audio file to our project by downloading it here and adding it to our project directory.
To follow along, we’ll need to download this .wav file. If you’d like to use another file, please note you’ll have to change the flagged_words and search_words for the project to work correctly.
Our project directory structure should look like this:
Back in our script_compliance.py, let’s add this code to our main function:
async def main():
deepgram = Deepgram(os.getenv("DEEPGRAM_API_KEY"))
with open(PATH_TO_FILE, 'rb') as audio:
source = {'buffer': audio, 'mimetype': 'audio/wav'}
transcription = await deepgram.transcription.prerecorded(source, {'punctuate': True })
speakers = await script_compliance(transcription)
asyncio.run(main())Here we are initializing Deepgram and pulling in our DEEPGRAM_API_KEY. We open our audio file and set the source to recognize it’s an audio/wav. Then we get the transcription and pass in the source and a Python dictionary {'punctuate': True}. The Deepgram punctuate option adds punctuation and capitalization to our transcript. Read more on how to use punctuate.
Lastly, let’s add our script_compliance function to the script_compliance.py file, just above our main function.
async def script_compliance(transcript_data: Dict) -> None:
if 'results' in transcript_data:
transcript = transcript_data['results']['channels'][0]['alternatives'][0]['transcript']
data = []
for key,value in flagged_words.items():
score_flagged_words = transcript.count(key)
if score_flagged_words:
data.append([key, value])
score_card.append(score_flagged_words)
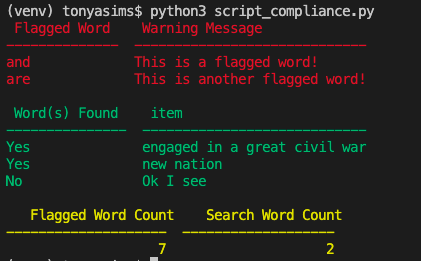
print(Fore.RED, tabulate(data, headers=["Flagged Word", "Warning Message"]))
print()
words = []
for item in search_words:
if item in transcript:
words.append(["Yes", item])
else:
words.append(["No", item])
print(Fore.GREEN, tabulate(words, headers=["Word(s) Found", "item"]))
print()
print(Fore.YELLOW, tabulate([[sum(score_card), len([w for w in words if w[0] == "Yes"])]], headers=["Flagged Word Count", "Search Word Count"]))Let’s break the code down.
if 'results' in transcript_data:
transcript = transcript_data['results']['channels'][0]['alternatives'][0]['transcript']The lines above get the transcript as a String type from the JSON response and store it in a variable called transcript.
data = []
for key,value in flagged_words.items():
score_flagged_words = transcript.count(key)
if score_flagged_words:
data.append([key, value])
score_card.append(score_flagged_words)
print(Fore.RED, tabulate(data, headers=["Flagged Word", "Warning Message"]))We create an empty list called data that will hold the flagged words and their warnings that we find in the transcript.
We then loop over the dictionary to search for flagged_words in the transcript and append those to our data list.
This line score_flagged_words = transcript.count(key) counts the number of occurrences of each key or flagged_words in our transcript and appends it to the score_card list.
Lastly, we print out the flagged words we find in red by passing in our data list and table headers.
The second part of the code works similarly.
words = []
for item in search_words:
if item in transcript:
words.append(["Yes", item])
else:
words.append(["No", item])
print(Fore.GREEN, tabulate(words, headers=["Word(s) Found", "item"]))We define a words list that will hold all of the search words we find in the transcript.
Then we loop through all the search_words that we defined at the beginning of the code example. If a search word is in the transcript, we append it to the words list with another value, Yes. Otherwise, we append it with a value No, which means we did not find the word in the transcript.
Lastly, we print the words list and table headers to the terminal in green.
Our last line of code prints out the scorecard if yellow of how many flagged words and search words we found. We get the sum of the scorecard, which holds our flagged words and uses a list comprehension to get how many search words we find in the transcript.
print(Fore.YELLOW, tabulate([[sum(score_card), len([w for w in words if w[0] == "Yes"])]], headers=["Flagged Word Count", "Search Word Count"]))Type python script_compliance.py or python3 script_compliance.py from your terminal to run our script.
Here’s an example of what our output would look like:
Congratulations on building a Python application with Deepgram to monitor script compliance! You can find the code here with instructions on how to run the project. If you have any questions, please feel free to reach out to us on Twitter at @DeepgramDevs.
If you have any feedback about this post, or anything else around Deepgram, we'd love to hear from you. Please let us know in our GitHub discussions .
More with these tags:
Share your feedback
Was this article useful or interesting to you?
Thank you!
We appreciate your response.



