

Have you ever wondered what you could build using voice-to-text and analytics? This article will discover how we can combine a speech recognition provider that transcribes audio to text with Python using Deepgram and speech-to-text analytics.
Analytics is all about measuring patterns in data to discover insights that help us make better decisions. These decisions could improve business capacity, raise sales, enhance communication between a customer service agent and customer, and much more.
If you’d like to jump ahead and grab the code for this project, please do so on our Deepgram Devs Github.
What We'll Build Together
This tutorial will use the Deepgram Python SDK to build a simple script that does voice transcription with Python. One of the many beauties of Deepgram is our diarize feature. We’ll use this feature to help us recognize which speaker is talking and assigns a transcript to that speaker. The diarize feature will help us recognize multiple speakers. We’ll see how to get the transcript from the audio and assign it to each speaker.
Then we’ll focus on analytics by measuring the following:
The amount of time each speaker spoke per phrase
The average amount of time they spoke
The total time of conversation for each speaker
Getting Started
Before we start, it’s essential to generate a Deepgram API key to use in our project. To grab one, we can go to our Deepgram console. Make sure to copy it and keep it in a safe place, as you won’t be able to retrieve it again and will have to create a new one. In this tutorial, we’ll use Python 3.10, but Deepgram supports some earlier versions of Python.
Next, let’s make a directory anywhere we’d like.
mkdir deepgram_analytics_projectThen change into that directory so we can start adding things to it.
cd deepgram_analytics_projectWe’ll also need to set up a virtual environment to hold our project and its dependencies. We can read more about those here and how to create one.
It’s recommended in Python to use a virtual environment so our project can be installed inside a container rather than installing it system-wide.
Now we can open up our favorite editor and create a file called deepgram_analytics.py. If you’d like to make it from the command line, do this:
touch deepgram_analytics.pyFinally, let’s install our dependencies for our project. Ensure our virtual environment is activated because we’ll install those dependencies inside. If your virtual environment is named venv then activate it.
source venv/bin/activateAfter activation, we install the dependencies, including:
The Deepgram Python SDK
The dotenv library, which helps us work with our environment variables
<!---->
pip install deepgram-sdk
pip install python-dotenvThe Code
Let’s open our deepgram_analytics.py file and include the following code at the top:
import asyncio
from deepgram import Deepgram
from dotenv import load_dotenv
from typing import Dict
import os
load_dotenv()
PATH_TO_FILE = 'premier_broken-phone.mp3'The first part is Python imports. We need to access the modules and libraries for our script to work correctly.
The load_dotenv() will help us load our api_key from an env file, which holds our environment variables.
The PATH_TO_FILE = 'premier_broken-phone.mp3' is a path to our audio file we’ll use to do the speech-to-text transcription.
Create an env file at the same level as our deepgram_analytics.py. Put the following inside of it:
DEEPGRAM_API_KEY = “YOUR_API_KEY”Where you’d replace YOUR_API_KEY with your api_key you got from Deepgram.
Next, let’s add the audio file to our project by downloading it here, and adding it to our project directory.
This audio file is a sample phone call from Premier Phone Services. To follow along, we’ll need to download this .mp3 file.
Our project directory structure should look like this:
Back in our deepgram_analytics.py let’s add this code to our main function:
async def main():
deepgram = Deepgram(os.getenv("DEEPGRAM_API_KEY"))
with open(PATH_TO_FILE, 'rb') as audio:
source = {'buffer': audio, 'mimetype': 'audio/mp3'}
transcription = await deepgram.transcription.prerecorded(source, {'punctuate': True, 'diarize': True})
speakers = await compute_speaking_time(transcription)
asyncio.run(main())Here we are initializing Deepgram and pulling in our DEEPGRAM_API_KEY. We open our audio file set the source to recognize it’s an audio/mp3. Then we get the transcription and pass in the source and a Python dictionary {'punctuate': True, 'diarize': True}. The diarize option helps us assign the transcript to the speaker. More on how to use diarize and the other options.
Lastly, let’s add our compute_speaking_time function to the deepgram_analytics.py file, just above our main function.
async def compute_speaking_time(transcript_data: Dict) -> None:
if 'results' in transcript_data:
transcript = transcript_data['results']['channels'][0]['alternatives'][0]['words']
total_speaker_time = {}
speaker_words = []
current_speaker = -1
for speaker in transcript:
speaker_number = speaker["speaker"]
if speaker_number is not current_speaker:
current_speaker = speaker_number
speaker_words.append([speaker_number, [], 0])
try:
total_speaker_time[speaker_number][1] += 1
except KeyError:
total_speaker_time[speaker_number] = [0,1]
get_word = speaker["word"]
speaker_words[-1][1].append(get_word)
total_speaker_time[speaker_number][0] += speaker["end"] - speaker["start"]
speaker_words[-1][2] += speaker["end"] - speaker["start"]
for speaker, words, time_amount in speaker_words:
print(f"Speaker {speaker}: {' '.join(words)}")
print(f"Speaker {speaker}: {time_amount}")
for speaker, (total_time, amount) in total_speaker_time.items():
print(f"Speaker {speaker} avg time per phrase: {total_time/amount} ")
print(f"Total time of conversation: {total_time}")
return transcriptLet’s break the code down.
if 'results' in transcript_data:
transcript = transcript_data['results']['channels'][0]['alternatives'][0]['words']These lines get the transcript as a String type from the JSON response and store it in a variable called transcript.
total_speaker_time = {}
speaker_words = []
current_speaker = -1We define an empty dictionary called total_speaker_time and empty list speaker_words. We also need to keep track of the current speaker as each person talks. The current_speaker variable is set to -1 because a speaker will never have that value, and we can update it whenever someone new is speaking.
for speaker in transcript:
speaker_number = speaker["speaker"]
if speaker_number is not current_speaker:
current_speaker = speaker_number
speaker_words.append([speaker_number, [], 0])
try:
total_speaker_time[speaker_number][1] += 1
except KeyError:
total_speaker_time[speaker_number] = [0,1]
get_word = speaker["word"]
speaker_words[-1][1].append(get_word)
total_speaker_time[speaker_number][0] += speaker["end"] - speaker["start"]
speaker_words[-1][2] += speaker["end"] - speaker["start"]Next, we loop through the transcript and find which speaker is talking. We append their speaker_number, an empty list [] to add their transcript, and 0, the total time per phrase for each speaker.
We use a try/except block to add to our total_speaker_time dictionary. We check if the key speaker_number is already in the dictionary. If so, then we just add how many times the speaker speaks total_speaker_time[speaker_number][1] += 1. If not in the dictionary, we add the key and its values total_speaker_time[speaker_number] = [0,1], with 0 as the time spoken in seconds and 1 is how many times they speak.
The below lines of code get the transcript from each speaker get_word = speaker["word"]. We then appended those to our speaker_words list. Finally, we get the total_speaker_time for each speaker by subtracting their end and start speaking times and adding them together.
get_word = speaker["word"]
speaker_words[-1][1].append(get_word)
total_speaker_time[speaker_number][0] += speaker["end"] - speaker["start"]Lastly, we do our analytics:
for speaker, words, time_amount in speaker_words:
print(f"Speaker {speaker}: {' '.join(words)}")
print(f"Speaker {speaker}: {time_amount}")
for speaker, (total_time, amount) in total_speaker_time.items():
print(f"Speaker {speaker} avg time per phrase: {total_time/amount} ")
print(f"Total time of conversation: {total_time}")
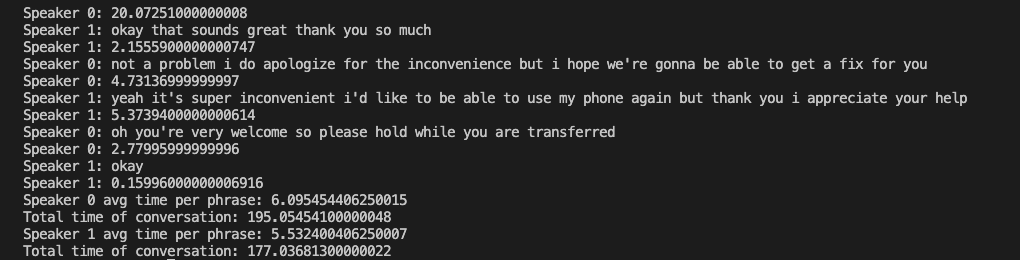
return transcriptIn the first for loop, we print out each speaker with their speaker number and their transcript. After each person talks, we calculate how long they spoke in that sentence.
In the second for loop, we calculate on average how long each person spoke and the total time of the conversation for each speaker.
To run our script type python deepgram_analytics.py or python3 deepgram_analytics.py from your terminal.
Here’s an example of what our output would look like:
Congratulations on transcribing audio to text with Python using Deepgram with speech-to-text analytics! You can find the code here with instructions on how to run the project. If you have any questions, please feel free to reach out to us on Twitter at @DeepgramDevs
If you have any feedback about this post, or anything else around Deepgram, we'd love to hear from you. Please let us know in our GitHub discussions .
More with these tags:
Share your feedback
Was this article useful or interesting to you?
Thank you!
We appreciate your response.



