Transfer Learning from Spanish to Portuguese: How Neighbors on the Map Also Share Vectors

April 13, 2022 in AI & Engineering

Transfer learning is one of the hottest topics of natural language processing-and, indeed, machine learning in general-in recent years. In this post, I want to share with you what transfer learning is, why it's so helpful when thinking about language-related tasks, and how we've used it to create a high-accuracy model for Portuguese based on the work that we'd already done for Spanish. In this blog post, we'll discuss some of our specific logic here, including the intuition of picking Spanish for helping Portuguese model training and the similarities between these languages on many levels. But to get started, let's talk about what transfer learning is and why it's so valued at Deepgram before diving into the specifics of Spanish and Portuguese.
What is Transfer Learning? A Very Brief History
In short, we can say that transfer learning is taking a model that has been trained on one task, and using it for a different one by changing its training data. Transfer learning started its journey with word vectors, which are static vectors for each word in the corpus. For our purposes, you can think of a vector as a way of describing the relationship between words in a large, abstract space. To get an idea of how this works, you can see an example of word vectors in Figure 1, below. If you look at the 1st box for the words man and woman, they're the same, but the word king is different because he's not an ordinary human; he's the king. Also man, woman, and king share the same third box, because they're all human. The fourth box of king is identical to man (baby blue), but woman has a different fourth box, pink. So king is more similar to man in this regard. 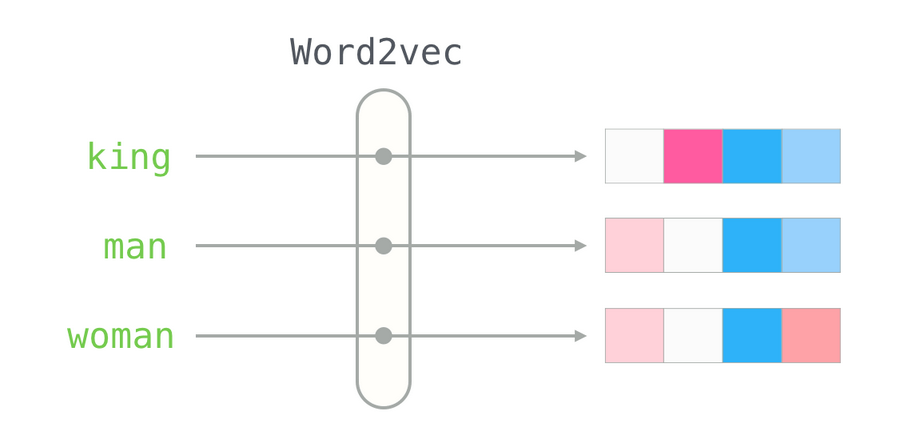
Figure 1. Word2vec, the ancestor of transfer learning, showing word similarities and differences (from https://jalammar.github.io/illustrated-word2vec/).
Next, contextual word vectors came with ELMo, or Embeddings from Language Models, which is "a type of deep contextualized word representation that models both (1) complex characteristics of word use (e.g., syntax and semantics), and (2) how these uses vary across linguistic contexts (i.e., to model polysemy)" (source.)). This provided a way to look at the relationship between words at a greater depth and with more . Finally transformers-a type of deep learning model that differentially weights input data-were developed to generate contextual word vectors as well as a sentence-level vector, which is even better for linguistic analysis.
At each step of this process, though, the goal remained the same-to look for good representations for our corpus words, which happen to be vectors. Both pretrained word vectors and transformers are trained on giant corpora, hence they know a lot about the target language's syntax and semantics. We feed pretrained vectors to our downstream models and the vectors bring what they know about the language, semantics of the words, and many surprising features to our models.
You can probably already see how this could be useful for language-related tasks. Speech recognition is the task of converting speech to text. Though speech recognition models are more sophisticated algorithms than text oriented statistical models, a neural network is still a neural network and weights are certainly used.
Hence, some weight re-using techniques are applicable to speech recognition, along with more sophisticated acoustic tricks. That is to say, once you have a model that works well for one language, it's relatively easy to give that model data for another language-especially one that's closely related-and see better results than if you started from scratch.
Why We Use Transfer Learning
At Deepgram, transfer learning is highly valued. For a specific language, when we want to train a new version of a specific model, we don't want to start from scratch. Instead, when we want to train a model for a brand new language, we want to transfer some knowledge from a similar language's model when possible. To illustrate the power of these processes, we'll look at a specific case of transfer learning-going from Spanish to Portuguese-to show how you can train a model for a new language from scratch by the help of a similar language's model.
Newsletter
Get Deepgram news and product updates
Why Spanish to Portuguese
Let's get started with the basic question of why we picked Spanish to help train our Portuguese model from scratch. Spanish and Portuguese come from the same language family and are closely related. Italian, French, Spanish, and Portuguese all belong to this language family-the Romance family. However, even if you didn't know that, a quick glance is enough for one to see the similarities between Spanish and Portuguese just by looking at a piece of text. Here's an example text pair, taken from Alice in Wonderland, to explain what we mean:
Spanish
No había nada tan notable en eso; Alicia tampoco pensó que fuera tan extraño escuchar al Conejo decirse a sí mismo: '¡Dios mío! ¡Oh querido! ¡Llegaré tarde!' (cuando lo pensó después, se le ocurrió que debería haberse preguntado por esto, pero en ese momento todo parecía bastante natural); pero cuando el Conejo sacó un reloj del bolsillo de su chaleco, lo miró y siguió corriendo, Alicia se puso de pie, porque le pasó por la mente que nunca antes había visto un conejo con chaleco... bolsillo, o un reloj para sacar de él, y ardiendo de curiosidad, corrió por el campo tras él, y afortunadamente llegó justo a tiempo para verlo caer por una gran madriguera debajo del seto.
Portuguese
Não havia nada tão notável nisso; Alice também não achou tão estranho ouvir Rabbit dizer para si mesmo: 'Meu Deus! Oh querida! Chegarei tarde!' (Quando ele pensou sobre isso depois, ocorreu-lhe que deveria ter se perguntado sobre isso, mas na época tudo parecia bastante natural); mas quando o Coelho tirou um relógio do bolso do colete, olhou para ele e correu, Alice levantou-se, porque lhe passou pela cabeça que nunca tinha visto um coelho com um colete... bolso, ou um relógio para levar. longe dele, e queimando de curiosidade, ela correu pelo campo atrás dele, felizmente chegando bem a tempo de vê-lo cair em uma grande toca sob a cerca viva.
For non-speakers of Spanish and Portuguese, it's totally reasonable to identify the above languages as the same-and you can quickly and easily find a lot of similarities between the two texts above, even if you don't know what they mean.
Similarities between Spanish and Portuguese
In this section, we'll compare Spanish and Portuguese phonetically, vocabulary-wise, and syntax-wise to better understand the ways that these languages are so similar in more depth.
Phonetic Similarities
The first major similarity between Spanish and Portuguese is acoustic similarity, which plays a key role for our transfer learning purposes. Here, acoustic or phonetic similarity means that the two languages use a set of sounds in their words that are very similar to one another. Consonants are almost identical in both languages, although Spanish has three extra affricates that Portuguese does not. Other than that, the consonants look the same on paper and they sound the same. Below, in Figure 2, we can see the phonetic alphabet for consonants of both languages, taken from the SAMPA website.
![]()
![]()
Figure 2. Spanish and Portuguese consonants, represented in SAMPA.
Vowels are a bit different. The Portuguese phonetic system has more vowels, and perceptually, Portuguese vowels are described as sounding different by Spanish speakers. In Figure 3 below we can see the Spanish and Pt vowels side by side, again taken from SAMPA website. ![]()
![]()
Figure 3. Spanish and Portuguese vowels in SAMPA.
Here, Spanish vowels look more minimalistic and the Portuguese side looks more crowded, since it has nasal vowels, like French. Still, there's a certain level of similarity.
Vocabulary Similarities
The final similarity between Spanish and Portuguese we want to discover is vocabulary similarity. Here, similar vocabulary means vocabulary strings that are either common or differ by a small edit distance-that is to say, one or two different letters or sounds. Compare the vocabulary words below, in Table 1, with Spanish on the left and Portuguese given on the right.
| Spanish | Portuguese |
|---|---|
| casa | casa |
| señora | senhora |
| para | para |
| ahora | ahora |
| cabeza | cabeça |
| toma | toma |
| vamos | vamos |
| cama | cama |
| gano | gano |
| bonita | bonita |
| cara | cara |
| centro | centro |
| estados | estados |
| libros | livros |
| opinión | opinião |
Table 1. Comparison of Spanish and Portuguese vocabulary items.
As we see, some words are literally the same and some words differ by an edit distance of one or two. This is great for transferring the word vectors from the Spanish model into the Portuguese model.
Syntactic Similarity
The final aspect of similarity between the two languages that we'll look at here is syntactic similarity-that is, how similar is the way that sentences and phrases are constructed? This is also related to transferring weights, as syntactic constructions are one of the things learned by the model. Since we'd like to uncover how these two languages relate to each other, let's compare the dependency trees for the phrases un perro pequeño and um cachorro pequeno meaning 'a small dog' in each language. These trees show us how words within a phrase or sentence are related to each other. I generated both dependency trees with displaCy, shown below in Figure 4.
![]()
![]()
Figure 4. Dependency trees of 'a small dog' (literally, "a dog small") in Spanish (top) and Portuguese (bottom).
In both dependency trees, we notice that the adjective comes after the noun. In both trees, the head is the noun perro/cachorro 'dog' and the adjective is attached to the head by the dependency relation adjective modifier, or amod. A determiner un/um 'a' is attached to the noun by the determiner, or det relation. We see that the above trees are identical; hence, if one learns the syntax of one Spanish/Portuguese pair, one can easily figure out the other language's syntax. Putting together this information, now we're ready to understand how we make use of transfer learning for training the very first speech recognition model of Portuguese from scratch.
Transferring our Model's Learning from Spanish to Portuguese
As we've seen, Spanish and Portuguese are very similar to one another in terms of their sounds, their vocabulary, and their sentence structures. If we go back to our discussion of vectors and weighting at the beginning, you can see why starting with a Spanish model would be an effective choice for creating a Portuguese model-the weights and vectors are likely to be extremely similar, with only a few small points of difference that the model will learn when it sees Portuguese data, making small adjustments as it goes. We can see how useful this is if we imagine instead starting with an English model to create one for Portuguese.
Although this would better than starting from zero (Portuguese and English are, after all, both languages, and they are related to one other, albeit more distantly), the number and magnitude of the adjustments would be much greater than when starting with Spanish, requiring a longer training process and more data from Portuguese to get the model to the same level of accuracy.
Wrapping Up
I hope this article gives you a good sense of what transfer learning is and why it can be so impactful in a case like Spanish and Portuguese where the languages are very similar. We've got more transfer learning material coming in the next few months, so stay tuned to learn more-you can sign up for our newsletter below to keep up-to-date on what's happening at Deepgram. Want to see the power of transfer learning first hand? Sign up for a free API key or contact us to get started using end-to-end deep learning for your speech recognition projects.
If you have any feedback about this post, or anything else around Deepgram, we'd love to hear from you. Please let us know in our GitHub discussions .
More with these tags:
Share your feedback
Was this article useful or interesting to you?
Thank you!
We appreciate your response.



