

Share
In this blog post
- What We’ll Need to Play Voice-Controlled Music Using AI
- Create a Python Virtual Environment
- The Code to Play Voice-Controlled Music with Python and AI
- Deepgram Python Code Explanation
- Next Steps to Extend the Voice-Controlled Python AI Music Example
- The Entire Python Code for the Voice-Controlled Music Example
Move over Beethoven. This tutorial will use Python and the Deepgram API speech-to-text audio transcription to play a piano with your voice. The song we’ll play is the first few phrases of Lady Gaga’s Bad Romance. It’s a simple piece in C Major, meaning no flats and sharps! We’ll only use pitches C, D, E, F, G, A, and B, and no black keys. What a beautiful chance for someone learning how to play the piano without a keyboard, tapping into the power of voice to play music!
After running the project, we'll see the GIF below when running the project as a PyGame application. A window will appear, and the piano will play the song. We'll hear the notes, which also light up on the keyboard.
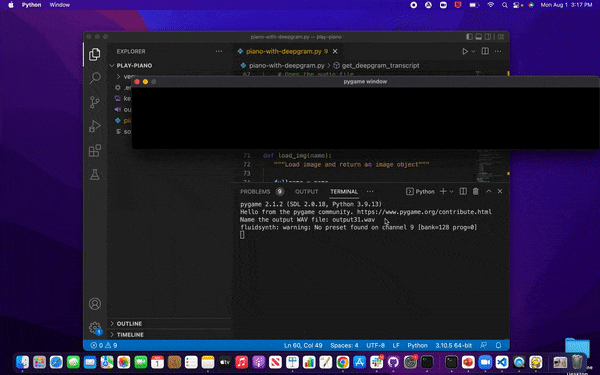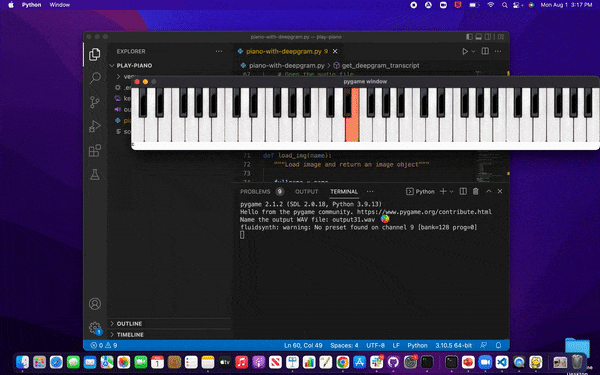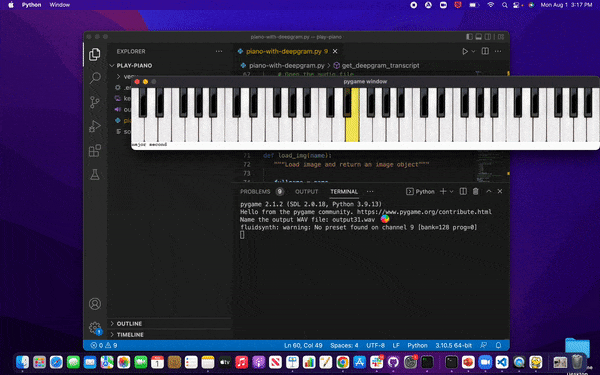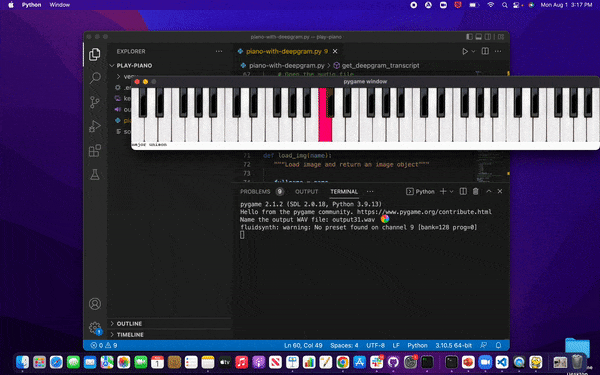
Let’s get started!
What We’ll Need to Play Voice-Controlled Music Using AI
This project requires macOS but is also possible with a Windows or Linux machine. We’ll also use Python 3.10 and other tools like FluidSynth and Deepgram Python SDK speech-to-text audio transcription.
FluidSynth
We need to install FluidSynth, a free, open-source MIDI software synthesizer that creates sound in digital format, usually for music. MIDI or Musical Instrument Digital Interface is a protocol that allows musical gear like computers, software, and instruments to communicate with one another. FluidSynth uses SoundFont files to generate audio. These files have samples of musical instruments like a piano that play MIDI files.
There are various options to install FluidSynth on a Mac. In this tutorial, we’ll use Homebrew for the installation. After installing Homebrew, run this command anywhere in the terminal:
brew install fluidsynthNow that FluidSynth is installed, let’s get our Deepgram API Key.
Deepgram API Key
We need to grab a Deepgram API Key from the console. It’s effortless to sign up and create an API Key here. Deepgram is an AI automated speech recognition voice-to-text company that allows us to build applications that transcribe speech-to-text. We’ll use Deepgram’s Python SDK and the Numerals feature, which converts a number from written format to numerical format. For example, if we say the number “three”, it would appear in our transcript as “3”.
One of the many reasons to choose Deepgram over other providers is that we build better voice applications with faster, more accurate transcription through AI Speech Recognition. We offer real-time transcription and pre-recorded speech-to-text. The latter allows uploading a file that contains audio voice data for transcribing.
Now that we have our Deepgram API Key let’s set up our Python AI piano project so we can start making music!
Create a Python Virtual Environment
Make a Python directory called play-piano to hold our project. Inside of it, create a new file called piano-with-deepgram.py, which will have our main code for the project.
We need to create a virtual environment and activate it so we can pip install our Python packages. We have a more in-depth article about virtual environments on our Deepgram Developer blog.
Activate the virtual environment after it’s created and install the following Python packages from the terminal.
pip install deepgram-sdk
pip install python-dotenv
pip install mingus
pip install pygame
pip install sounddevice
pip install scipyLet’s go through each of the Python packages.
deepgram-sdkis the Deepgram Python SDK installation that allows us to transcribe speech audio, or voice, to a text transcript.python-dotenvhelps us work with environment variables and our Deepgram API KEY, which we’ll pull from the.envfile.mingusis a package for Python used by programmers and musicians to make and play music.pygameis an open-sourced Python engine to help us make games or other multimedia applications.sounddevicehelps get audio from our device’s microphone and records it as a NumPy array.scipyhelps writes the NumPy array into a WAV file.
We need to download a few files, including keys.png, which is the image of the piano GUI. The other file we need is the Yamaha-Grand-ios-v1.2 from this site. A SoundFont contains a sample of musical instruments; in our case, we’ll need a piano sound.
The Code to Play Voice-Controlled Music with Python and AI
We’ll only cover the Deepgram code in this section but will provide the entire code for the project at the end of this post.
file_name = input("Name the output WAV file: ")
AUDIO_FILE = file_name
fs = 44100
duration = 30.0
def record_song_with_voice():
print("Recording.....")
record_voice = sd.rec(int(duration * fs) , samplerate = fs , channels = 1)
sd.wait()
write(AUDIO_FILE, fs,record_voice)
print("Finished.....Please check your output file")
async def get_deepgram_transcript():
deepgram = Deepgram(os.getenv("DEEPGRAM_API_KEY"))
record_song_with_voice()
with open(AUDIO_FILE, "rb") as audio:
source = {"buffer": audio, "mimetype": "audio/wav"}
response = await deepgram.transcription.prerecorded(source, {"punctuate": True, "numerals": True})
return response
async def get_note_data():
note_dictonary = {
'1': 'C',
'2': 'D',
'3': 'E',
'4': 'F',
'5': 'G',
'6': 'A',
'7': 'B'
}
get_numbers = await get_deepgram_transcript()
data = []
if 'results' in get_numbers:
data = get_numbers['results']['channels'][0]['alternatives'][0]['words']
return [note_dictonary [x['word']] for x in data]
data = asyncio.run(get_note_data())Deepgram Python Code Explanation
This line of code prompts the user to create a name of the audio file so that the file will save in .wav format:
file_name = input("Name the output WAV file: ")Once the file is created the function record_song_with_voice gets called inside the get_deepgram_transcript method.
def record_song_with_voice():
print("Recording.....")
record_voice = sd.rec(int(duration * fs) , samplerate = fs , channels = 1)
sd.wait()
write(AUDIO_FILE, fs,record_voice)
print("Finished.....Please check your output file")Inside the record_song_with_voice function, this line records the audio.
record_voice = sd.rec(int(duration * fs) , samplerate = fs , channels = 1)Where duration is the number of seconds it takes to record an audio file, and fs represents the sampling frequency. We set both of these as constants near the top of the code.
Then we write the voice recording to an audio file using the .write() method. That line of code looks like this:
write(AUDIO_FILE, fs,record_voice)Once the file is done writing, this message will print to the terminal ”Finished.....Please check your output file", which means the recording is complete.
The function get_deepgram_transcript is where most of the magic happens. Let’s walk through the code.
async def get_deepgram_transcript():
deepgram = Deepgram(os.getenv("DEEPGRAM_API_KEY"))
record_song_with_voice()
with open(AUDIO_FILE, "rb") as audio:
source = {"buffer": audio, "mimetype": "audio/wav"}
response = await deepgram.transcription.prerecorded(source, {"punctuate": True, "numerals": True})
return responseHere we initialize the Deepgram Python SDK. That’s why it’s essential to grab a Deepgram API Key from the console.
deepgram = Deepgram(os.getenv("DEEPGRAM_API_KEY"))We store our Deepgram API Key in a .env file like so:
DEEPGRAM_API_KEY="abc123"The abc123 represents the API Key Deepgram assigns us.
Next, we call the external function record_song_with_voice(), which allows us to record our voice and create a .wav file that will pass into Deepgram as pre-recorded audio.
Finally, we open the newly created audio file in binary format for reading. We provide key/values pairs for buffer and a mimetype using a Python dictionary. The buffer’s value is audio, the object we assigned it in this line with open(AUDIO_FILE, "rb") as audio: The mimetype value is audio/wav, which is the file format we’re using, which one of 40+ different file formats that Deepgram supports. We then call Deepgram and perform a pre-recorded transcription in this line: response = await deepgram.transcription.prerecorded(source, {"punctuate": True, "numerals": True}). We pass in the numerals parameter so that when we say a number, it will process in numeric form.
with open(AUDIO_FILE, "rb") as audio:
source = {"buffer": audio, "mimetype": "audio/wav"}
response = await deepgram.transcription.prerecorded(source, {"punctuate": True, "numerals": True})
return responseThe last bit of code to review is the get_note_data function, doing precisely that: getting the note data.
async def get_note_data():
note_dictonary = {
'1': 'C',
'2': 'D',
'3': 'E',
'4': 'F',
'5': 'G',
'6': 'A',
'7': 'B'
}
get_numbers = await get_deepgram_transcript()
data = []
if 'results' in get_numbers:
data = get_numbers['results']['channels'][0]['alternatives'][0]['words']
return [note_dictonary [x['word']] for x in data]
data = asyncio.run(get_note_data())We have a Python dictionary with keys from ‘1’ to ‘7’ corresponding to every note in the C Major scale. For example, when we say the number 1 that plays the note C, saying the number 2 will play the ‘D’ note, and so on:
note_dictonary = {
'1': 'C',
'2': 'D',
'3': 'E',
'4': 'F',
'5': 'G',
'6': 'A',
'7': 'B'
}Here’s how that would look on a piano. Each note in C Major is labeled, and located above is a corresponding number. The numbers 1 - 7 are critical, representing a single note in our melody.
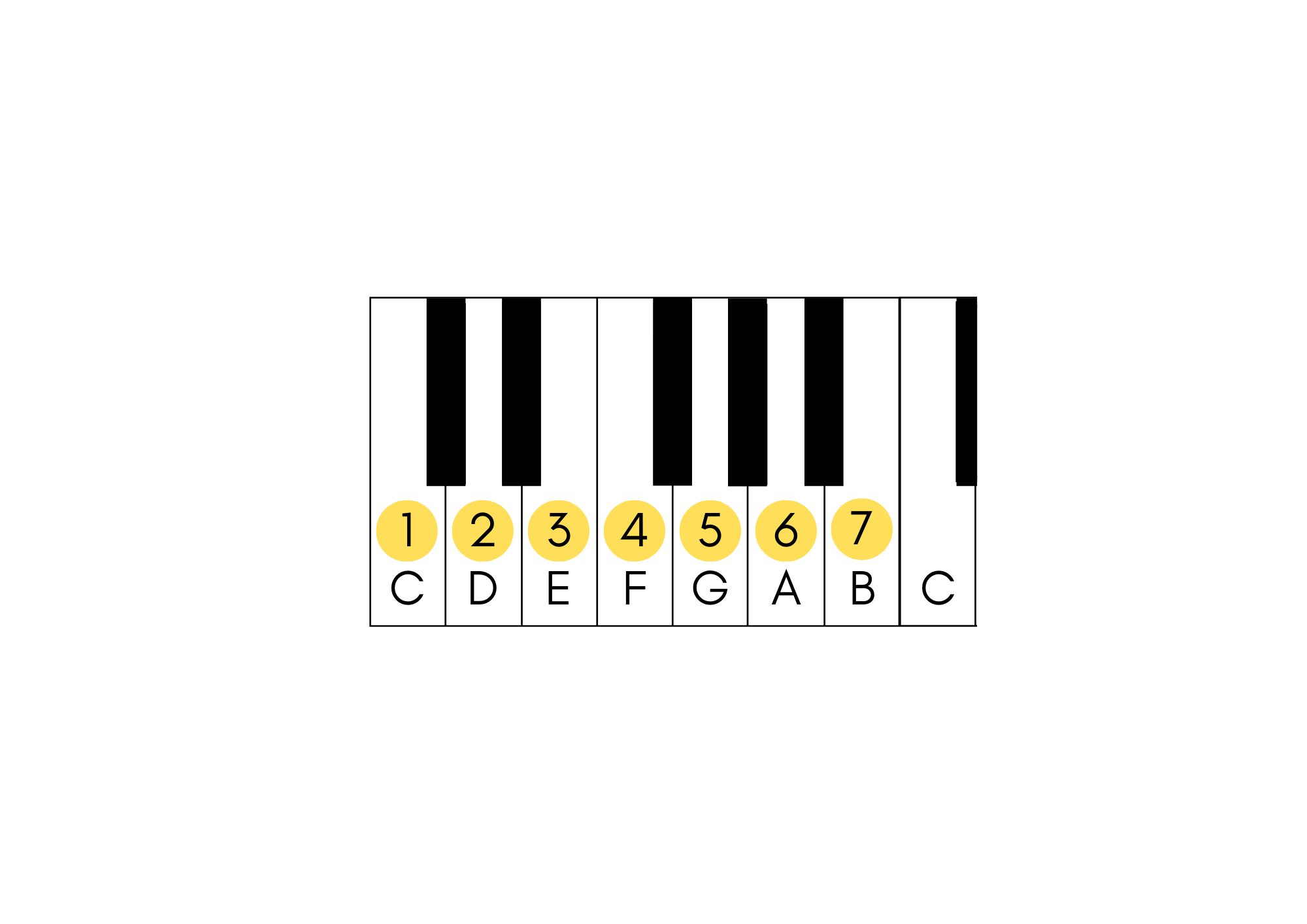
Next, we get the numerals from the Deepgram pre-recorded transcript get_numbers = await get_deepgram_transcript().
We then create an empty list called data and check if there are any results in the parsed response we get back from Deepgram. If results exist, we get that result and store it in data:
data = []
if 'results' in get_numbers:
data = get_numbers['results']['channels'][0]['alternatives'][0]['words']Example output may look like the below, depending on which song we create.
[
{'word': '1', 'start': 2.0552316, 'end': 2.4942129, 'confidence': 0.99902344, 'punctuated_word': '1'},
{'word': '4', 'start': 2.8533795, 'end': 3.172639, 'confidence': 0.9980469, 'punctuated_word': '4'},
{'word': '3', 'start': 3.6116204, 'end': 4.1116204, 'confidence': 0.9975586, 'punctuated_word': '3'}
]We notice that the word key in the above response correlates to a numeral we speak into the microphone when recording the song.
We can now create a new list that maps each numeral to a note on the piano, using a list comprehension return [note_dictonary [x['word']] for x in data].
To run the project, we’ll need all the code. See the end of this post.
Then in our terminal, we can run the project by typing:
python3 piano-with-deepgram.pyNow, use our voice to say the following numerals, which correspond to piano notes, to play the first few phrases from Lady Gaga’s song Bad Romance:
12314 3333211 12314 3333211
Next Steps to Extend the Voice-Controlled Python AI Music Example
Congratulations on getting to the end of the tutorial! We encourage you to try and extend the project to do the following:
Play around with the code to play songs in different octaves
Play voice-controlled music that has flats and sharps
Tweak the code to play voice-controlled music using whole notes and half notes
When you have your new masterpiece, please send us a Tweet at @DeepgramAI and showcase your work!
The Entire Python Code for the Voice-Controlled Music Example
# -*- coding: utf-8 -*-
from pygame.locals import *
from mingus.core import notes, chords
from mingus.containers import *
from mingus.midi import fluidsynth
from os import sys
from scipy.io.wavfile import write
from deepgram import Deepgram
from dotenv import load_dotenv
import asyncio, json
import pygame
import os
import time
import sounddevice as sd
load_dotenv()
file_name = input("Name the output WAV file: ")
# Audio File with song
AUDIO_FILE = file_name
SF2 = "soundfont.sf2"
OCTAVES = 5 # number of octaves to show
LOWEST = 2 # lowest octave to show
FADEOUT = 0.25 # 1.0 # coloration fadeout time (1 tick = 0.001)
WHITE_KEY = 0
BLACK_KEY = 1
WHITE_KEYS = [
"C",
"D",
"E",
"F",
"G",
"A",
"B",
]
BLACK_KEYS = ["C#", "D#", "F#", "G#", "A#"]
fs = 44100
duration = 30.0
def record_song_with_voice():
print("Recording.....")
record_voice = sd.rec(int(duration * fs) , samplerate = fs , channels = 1)
sd.wait()
write(AUDIO_FILE, fs,record_voice)
print("Finished.....Please check your output file")
async def get_deepgram_transcript():
# Initializes the Deepgram SDK
deepgram = Deepgram(os.getenv("DEEPGRAM_API_KEY"))
# call the external function
record_song_with_voice()
# Open the audio file
with open(AUDIO_FILE, "rb") as audio:
# ...or replace mimetype as appropriate
source = {"buffer": audio, "mimetype": "audio/wav"}
response = await deepgram.transcription.prerecorded(source, {"punctuate": True, "numerals": True})
return response
def load_img(name):
"""Load image and return an image object"""
fullname = name
try:
image = pygame.image.load(fullname)
if image.get_alpha() is None:
image = image.convert()
else:
image = image.convert_alpha()
except pygame.error as message:
print("Error: couldn't load image: ", fullname)
raise SystemExit(message)
return (image, image.get_rect())
if not fluidsynth.init(SF2):
print("Couldn't load soundfont", SF2)
sys.exit(1)
pygame.init()
pygame.font.init()
font = pygame.font.SysFont("monospace", 12)
screen = pygame.display.set_mode((640, 480))
(key_graphic, kgrect) = load_img("keys.png")
(width, height) = (kgrect.width, kgrect.height)
white_key_width = width / 7
# Reset display to wrap around the keyboard image
pygame.display.set_mode((OCTAVES * width, height + 20))
pygame.display.set_caption("mingus piano")
octave = 4
channel = 8
# pressed is a surface that is used to show where a key has been pressed
pressed = pygame.Surface((white_key_width, height))
pressed.fill((0, 230, 0))
# text is the surface displaying the determined chord
text = pygame.Surface((width * OCTAVES, 20))
text.fill((255, 255, 255))
playing_w = [] # white keys being played right now
playing_b = [] # black keys being played right now
quit = False
tick = 0.0
def play_note(note):
"""play_note determines the coordinates of a note on the keyboard image
and sends a request to play the note to the fluidsynth server"""
global text
octave_offset = (note.octave - LOWEST) * width
if note.name in WHITE_KEYS:
# Getting the x coordinate of a white key can be done automatically
w = WHITE_KEYS.index(note.name) * white_key_width
w = w + octave_offset
# Add a list containing the x coordinate, the tick at the current time
# and of course the note itself to playing_w
playing_w.append([w, tick, note])
else:
# For black keys I hard coded the x coordinates. It's ugly.
i = BLACK_KEYS.index(note.name)
if i == 0:
w = 18
elif i == 1:
w = 58
elif i == 2:
w = 115
elif i == 3:
w = 151
else:
w = 187
w = w + octave_offset
playing_b.append([w, tick, note])
# To find out what sort of chord is being played we have to look at both the
# white and black keys, obviously:
notes = playing_w + playing_b
notes.sort()
notenames = []
for n in notes:
notenames.append(n[2].name)
# Determine the chord
det = chords.determine(notenames)
if det != []:
det = det[0]
else:
det = ""
# And render it onto the text surface
t = font.render(det, 2, (0, 0, 0))
text.fill((255, 255, 255))
text.blit(t, (0, 0))
# Play the note
fluidsynth.play_Note(note, channel, 100)
time.sleep(0.50)
async def get_note_data():
note_dictonary = {
'1': 'C',
'2': 'D',
'3': 'E',
'4': 'F',
'5': 'G',
'6': 'A',
'7': 'B'
}
get_numbers = await get_deepgram_transcript()
data = []
if 'results' in get_numbers:
data = get_numbers['results']['channels'][0]['alternatives'][0]['words']
return [note_dictonary [x['word']] for x in data]
data = asyncio.run(get_note_data())
i = 0
while i < len(data):
# Blit the picture of one octave OCTAVES times.
for x in range(OCTAVES):
screen.blit(key_graphic, (x * width, 0))
# Blit the text surface
screen.blit(text, (0, height))
# Check all the white keys
for note in playing_w:
diff = tick - note[1]
# If a is past its prime, remove it, otherwise blit the pressed surface
# with a 'cool' fading effect.
if diff > FADEOUT:
fluidsynth.stop_Note(note[2], channel)
playing_w.remove(note)
else:
pressed.fill((0, ((FADEOUT - diff) / FADEOUT) * 255, 124))
screen.blit(pressed, (note[0], 0), None, pygame.BLEND_SUB)
if tick > i/4:
play_note(Note(data[i], octave))
i += 1
# if i == len(data):
# i = 0
pygame.display.update()
tick += 0.005 # or 0.001 or 0.0001If you have any feedback about this post, or anything else around Deepgram, we'd love to hear from you. Please let us know in our GitHub discussions .
More with these tags:
Share your feedback
Was this article useful or interesting to you?
Thank you!
We appreciate your response.




{kind=link}