What is ASR?

October 16, 2018 in AI & Engineering

Share
In this blog post
Automatic Speech Recognition, also known as ASR or Voice Recognition, is a term you've heard a lot in recent years. In a sentence,
ASR is series of technologies used to automatically process audio data (phone calls, voice searches on your phone, podcasts, etc.) into a format computers can understand. Often readable text, it is a necessary first step to figuring out what cool information is hiding in voice recordings.
Since its fledgeling beginnings in the 1950s, ASR has come a long way-once an ARPA (DARPA) project in the 70's, then a frustrating dictation product in the 90's to a buzzword today.

News of the successful launch of the first artificial satellite Sputnik by the USSR (1957) spurred President Eisenhower to create ARPA (Advanced Research Projects Agency) in 1958. This agency is responsible for the creation of some minor 20th century inventions such as the computer mouse and the Internet, as well as every Tom Clancy plot ever.
Since the advent of products like Siri, Alexa, and Google Home there has been a lot of excitement around the term. This is because ASR technologies are the driving force behind a wide array of modern technologies. If you have a smartphone -66% of living humans do (and at least one Rhesus monkey), then you have ASR technologies at your fingertips. And it's used by 83% of business to transcribe speech, according to respondents in The State of Voice 2022. However, like so many oft-thrown-about terms, ASR seems to remain a nebulous term.
What is ASR really?
What does ASR do?
How can I use ASR?
What are the limitations of ASR?
Why should I care about it?
Our goal in this and subsequent articles is to answer some of these questions and, perhaps, ask a few questions of our own.
What is ASR?
Well, as you may have gathered from the first sentence above, ASR stands for Automatic Speech Recognition. The purpose of ASR is to convert audio data into data formats that data scientists use to get actionable insights for business, industry and academia. Most often, that data format is a readable transcript. Sounds simple, and in principle it is. Let's unpack the three words behind ASR so we can make more sense of what is going on:
The term automatic makes reference that after a certain point, machines are doing some human task without any human intervention. Speech data in, machine-readable data out.
The term speech tells us that we are working with audio data -technically any audio data. These include noisy customer recordings from an angry customer calling from a 16 lane highway in Los Angeles, to super-crisp, extra bass-y podcast audio.
The term recognition tells us that our goal here is to convert audio into a format that computers can understand (often a text a transcript). In order to do neat things with audio data, such trigger a command to buy something online (think: OK Google) or figure out what sort of phone sales interactions lead to better sales numbers, you need to convert audio data into a parsable data format for machines (and humans) to analyze.
However, not all ASR is made equal. There are many approaches to converting speech into text-some better than others....
3 Ways to Do Automatic Speech Recognition
There are essentially three ways to do automatic speech recognition:
The old way
The Frankenstein approach
The new way (End-to-End Deep Learning)
ASR technologies began development in the 1950 and 1960s, when researchers made hard-wired (vacuum tubes, resistors, transistors and solder) systems that could recognize individual words -not sentences or phrases. That technology, as you might imagine, is essentially obsolete (I do suspect, however, that those people who are into vacuum tube amps, might still be into it).
Newsletter
Get Deepgram news and product updates
1. The Old Way
In the 1970's, with ARPA funding, a team at Carnegie Melon University developed technology that could produce transcripts from context-specific speech, e.g. voice-controlled versions of chess, chart-plotting for GIS and navigation and office-environment document management. Briefly, in that approach (revolutionary at the time) audio was converted into machine-readable text in a series of logical steps: load audio, reduce noise, cut up into meaningful sounds, statistically guess the sounds, statistically combine said sounds to guess the words, compare resulting options, output a best guess. In the 1990s, this approach (with improvements) allowed Nuance to make a piece of software (Dragon Translate) that was not too bad at transcribing single speakers when they spoke clearly in low-noise environments. Unfortunately, it took many hours to train the software to transcribe what one person said -again, assuming perfect acoustic surroundings -like the back of my closet, where all the clothes muffle any noise, especially my gentle cries of frustration. Products like these had one major limitation: they could only reliably convert speech to text for one person. This is because no two people speak alike. Among any two speakers there are variations in pronunciation, tone, word-choice, grammar choice, even amount of lung pressure, that from a mathematical perspective (computers speak math) make what they say completely different-even if it's the same to you and me. In fact, even if the same person utters a sentence twice, the sounds when recorded and measured are mathematically different!
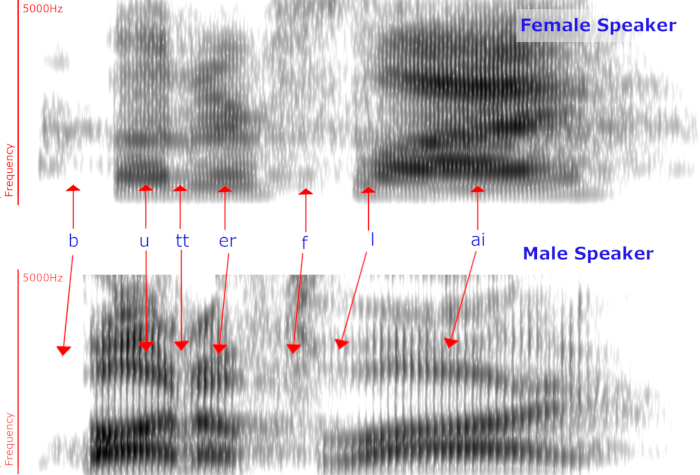
These are two spectrograms of two people saying the same word: butterfly. Spectrograms are one way to visualize audio data. As you can see, these two spectrograms are very different from one another. Pay special attention to the slopes of the darker lines and their relative shapes. Same word to our human, meat-based brains, two mathematical realities for silicon brains!
Though unable to transcribe the utterances of multiple speakers, these ASR-based, personal transcription tools and products were revolutionary and had legitimate business uses.
2. Franken-ASR
In the mid-2000s, companies like Nuance, Google and Amazon figured out that they could make the old-school 1970s approach to ASR work for multiple speakers and better in noisy environments. To do this, these big companies replaced a small part of their speech recognition contraption with a new gizmo: neural networks. Rather than having to train ASR to understand one individual, these franken-ASRs were able to understand multiple speakers decently well - a considerable feat given the acoustic and mathematical realities of spoken language (see above). The reason that this is possible is because these neural-network algorithms can "learn on their own" when given certain stimuli. In the case of stimuli for ASR, that stimulus is painstakingly human-transcribed audio data. As a result, some pretty neat products were made possible. However, the downside is that by slapping a neural network on top of the older machinery (recall, based on techniques from the 1970s), results in bulky, complex and resource hungry machines like the DeLorean from Back-to-the-Future or my college bicycle: a franken-bike that worked, when the tides and winds were just right, usually, except when it didn't. (note: just cause you add a Mr. Fusion to your time-machine/bicycle, it does not mean that the other parts will work any better).

No picture of my franken-bike available as it is still classified. Above, Boris Karloff portrays Frankenstein's monster in the 1931 Hollywood classic.
While clunky, the hybrid approach to ASR developed in the mid-2000s, works well enough for certain applications, after all, you don't expect to solve any real data questions with Siri. Philosophical ones however...
3. End-to-End Deep Learning
The newest approach, end-to-end deep learning ASR, leverages the power of neural nets and scraps the clunky 1970's approach. Essentially, this new approach allows you to do something that was not possible even 2 years ago: to quickly train the ASR to recognize dialects, accents and industry-specific word sets and to do so accurately. Think of this as a purpose-built, Mr. Fusion bicycle, no rusty bike-frames or ill-fated auto brands. The magic behind this depends on a few things: break-through math from the 80's, computing power/technology from the mid 2010s, big data, and the ability to rapidly innovate. This last idea is important. Being able to try new architectures, technologies and approaches is critical. Consider something known as the Concorde syndrome: if a company university (or any entity) has invested a lot of time and money in a huge machine that works more or less, they won't have much motivation to start from scratch even if doing so makes engineering/financial/logical sense.

The Concorde project, first devised before humans walked on the moon, and completed long after, wound up costing 20 times the projected amount. In 2003, when it made its last commercial flight, a seat on the plane cost about $5,500 ($7,300 in 2018 dollars).
With modern approaches to ASR (specifically end-to-end deep learning approaches) we can build ASR systems that allow us to make highly accurate transcripts of audio data that have specialized words, accents, noise conditions etc., but with a technology that scales well and is always evolving. For example, modern ASR systems are able to further overcome noise and speaker variability issues by taking linguistic context into account. This means that computers are learning to distinguish the meaning of the word "tree" when found in conversations about family versus ones about botany. Legacy ASR systems built using the hybrid, franken-ASR are designed to deal with "general" audio, not specialized audio for industry, business or even academic purposes. In other words, they provide generalized speech recognition and cannot realistically be trained to improve on your speech data.
Questions to be answered...
Hopefully, by now, you have had a few of your questions answered. Most likely you also have other questions burning in your mind. For example, you might have gathered that ASR-in some form or another-is behind products like OK Google and Siri, but you may wonder:
Where else can I find ASR?
What can you do with a good transcript of audio data?
What sorts of secrets lie hidden in all that talk?
What are the steps to test ASR providers?
ASR is the technology that, deployed intelligently, creates highly accurate transcripts and opens the door to insights that lead to lower costs, higher revenue and academic discovery.
If you have any feedback about this post, or anything else around Deepgram, we'd love to hear from you. Please let us know in our GitHub discussions .
More with these tags:
Share your feedback
Was this article useful or interesting to you?
Thank you!
We appreciate your response.




{kind=link}