What is Word Error Rate (WER)?

December 4, 2018 in AI & Engineering

Word Error Rate (WER) is a common metric used to compare the accuracy of the transcripts produced by speech recognition APIs. Speech recognition APIs are used to surface actionable insights from large volumes of audio data in addition to powering robust IVRs and voice-command-enabled devices such as the Amazon Echo. Product developers and data scientists can choose from many speech recognition APIs. How are they to judge which will be a good fit for their application? When evaluating speech recognition APIs, the first metric they'll consider is likely to be WER. However, a metric has no value unless we understand what it tells us. Let's break down WER to find out what it means and how useful a metric it is.
How to Calculate WER
Word error rate is the most common metric used today to evaluate the effectiveness of an automatic speech recognition system (ASR). It is simply calculated as:
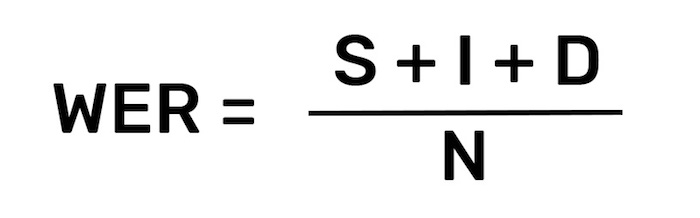
S stands for substitutions (replacing a word). I stands for insertions (inserting a word). D stands for deletions (omitting a word). N is the number of words that were actually said Note: WER will be calculated incorrectly if you forget to normalize capitalization, punctuation, numbers, etc. across all transcripts
Imagine you are using speech recognition to find out why customers are calling. You have thousands of hours of calls, and you want to automatically categorize the calls. On playback, one such call starts as follows:

However, when the machine transcribes this same call, the output may look like this:
![]()
If you compare this transcript with the one above, it's clear that the machine's one has problems. Let's analyze them in terms of our WER formula.
In line one, we see that the word "Upsilon", has been interpreted as "up silent". We will say that this represents (1) substitution-a wrong word in place of the correct word-and (1) insertion-adding of a word that was never said.
On line two, we have (1) substitution: "brat" instead of "Pratt."
On line three we have (1) substitution: "designed" instead of "declined."
On line four we have (2) substitutions: "cart" instead of "card" and "because" instead of cause. On this line we also have (1) deletion: the word "it" is gone.
The original phone call contained 36 words. With a total of 9 errors, the WER comes out to 25%.
What WER Really Means
How well a speech recognition API can transcribe audio depends on a number of factors, which we will discuss below. Before we do, we must ask ourselves the most important question one can ask when assessing a speech recognition system: "is the transcript usable for my purposes?" Let's consider our example. This is a good transcription if you are trying to figure whether customers are calling to solve issues with credit cards or debit cards. However, if your goal is to figure why out each person called your call center (to deal with a declined card, lost card, etc.) then this phone call would likely get mis-sorted. This is because the system did not properly transcribe a keyword: "declined." When a speech recognition API fails to recognize words important to your analysis, it is not good enough-no matter what the WER is. Word error rate, as a metric, does not give us any information about how the errors will affect usability for users. As you can see, you the human can read the flawed transcript and still manage to figure out the problem. The only piece of information you might have trouble reconstructing is the name and location of the gas station. Unfamiliar proper names are troublesome for both humans and machines.
A Low WER can be Deceptive-Depending on the Data
Depending on the data we want to look at, even low word error rate transcripts may prove less useful than expected. For example, notice how on line 4, "'cause" was transcribed as "because" and the object pronoun "it" was omitted. These two errors may not matter, especially if your goal is to find out why customers are calling. If the speech recognition API had not made these errors, we would have a 19.4% WER-almost as good as it gets for general, off-the-shelf speech recognition. But, as you can see, a low(er) error rate does not necessarily translate into a more useful transcript. This is because adverbs like "because" and object pronouns like "it" are not of much interest to us in this case.
"You can have two systems with similar accuracy rates that produce wildly differently transcripts in terms of understandability. You can have two different systems that are similar in terms of accuracy but maybe one handles particular vocabulary that's germane to your application better than the other. There's more than just accuracy at the heart of it."
—Klint Kanopka Stanford Ph.D. Researcher
While WER is a good, first-blush metric for comparing the accuracy of speech recognition APIs, it is by no means the only metric which you should consider. Importantly, you should understand how the speech recognition API will deal with your data. What words will it transcribe with ease? What words will give it trouble? What words matter to you? In our example, the words "declined" and "credit card" are likely the ones we want to get right every time.
What Affects the Word Error Rate?
A 25% word error rate is about average for "off the shelf" speech recognition APIs like Amazon, Google, IBM Watson, and Nuance. The more technical, the more industry-specific, the more "accented" and the more noisy your speech data is, the less likely that a general speech recognition API (or humans) will do as well.
Technical and Industry-specific Language
There's a reason that human transcriptionists charge more for technical or industry-specific language. It simply takes more time and effort for human brains to reliably recognize niche terms. The language that is normal to call center manager, a lawyer or a business executive is rare elsewhere. As a result, speech recognition systems trained on "average" data also struggle with more specialized words. As you'd guess, the technical language was created for a reason and accordingly, it's the language that businesses care the most about.
Accented Language
Accent is a highly relative, very human concept. This author has a strong accent in Dublin, but almost none in New York. The speech recognition systems built by large companies such as Google, Nuance and IBM are very familiar with the sort of English one hears on TV: "general American English" and RP (received pronunciation-the form of British English spoken by the Queen, the BBC and Oxford graduates). They are not necessarily familiar with the "real" English spoken in Palo Alto, CA; Athens, Georgia; New Dehli, India or Edinburgh, Scotland. However, companies are interested in the "real" language since a very tiny subset of their employees are TV anchors.

In New Delhi-English is spoken natively and non-natively by a large percentage of the population. Photo Credit: Raghu Nayyar.
Therefore, if your data has a wider variety of accents (it almost certainly does), or is limited to a set of accents not well represented in the data used to create general speech recognition APIs, then you probably need a custom-built model to really get a good look at your data.
Noisy Data
Wouldn't it be nice if everyone who called us to do business did so from a sound studio? Wouldn't you love that crisp, bassy, noise-free audio? Better yet, how about they didn't call us over the phone, since VoIP and traditional phone systems compress audio, cut off many frequencies and add noise artifacts? The real world is full of noise. Phone calls are inherently bad quality, people call while rushing to work, or walking by a seemingly endless line of jackhammers, fire engines and screaming 4-month-olds.

Somehow, human transcribers do okay with such noisy data, and speech recognition APIs, if properly trained, can do okay too. However, as you can imagine, when companies advertise super-low word error rates, these are not the WERs they get when transcribing audio captured at Iron Maiden concerts held in the middle of 16 lane interstate highways.
Newsletter
Get Deepgram news and product updates
Choosing an Speech Recognition API
Speech recognition APIs are fantastic tools that allow us to look into vast amounts of audio data in order to learn meaningful things about our customers, our operations and the world in general. WER is one metric that allows us to compare speech recognition APIs. However, as it is the case in any science, there is no one "best" metric.
I like analogies, so here is one: Asking which is the best metric to judge the quality of a bicycle could end in disaster. If your say "weight is the best metric, the lighter the better," then people like me who use their bikes to carry heavy groceries, 2 months of laundry and the occasional 2x4 would be in trouble. If you said "the number of pannier racks on a bike" is a good metric, then Tour de France cyclists would become a lot more winded, faster. All in all, you need to choose what's right for you.

This bike is a robust touring bike with pannier racks-great for shopping and 10,000 mile tours, bad for Tour de France. Photo credit: Derek Thomson
When you want to decide which speech recognition API to use, ask yourself:
Are there particular audio types that you need the speech recognition API to perform well on (phone call, TV, radio, meetings)?
Are there certain words or accents that the speech recognition API should do well on?
Can you customize the API to perform better on your data?
For more, check out our step by step guide on how to evaluate an ASR provider or have us evaluate the ASR provider for you.
If you have any feedback about this post, or anything else around Deepgram, we'd love to hear from you. Please let us know in our GitHub discussions .
More with these tags:
Share your feedback
Was this article useful or interesting to you?
Thank you!
We appreciate your response.



