What's the Best Infrastructure for Machine Learning — AI Show

November 30, 2018 in AI & Engineering

Scott: Welcome to the AI Show. Today we ask the question: What's the best infrastructure for machine learning?
Susan: We have seen a revolution recently and we can point to one of the big enablers, which has been GPUs. We've talked about this a whole lot. GPUs have not always been here.
Scott: Machine learning has been going on for a while. GPUs haven't been the end-all-be-all over all of time.
Susan: Exactly! Back in the '50s you think they had GPUs to crank on? No, they didn't.
Scott: They barely had CPUs to crank on. I don't think they had that really. They had some kind of calculator type machines.
Susan: The roots of machine learning really goes back to the '50s. A lot of great experiments on computers of the day started back there. Minsky wrote his great article describing all these problems in the '50s.
What were the architectures through the ages?
Scott: You have tubes, and huge rooms.
Susan: A series of tubes.

Scott: Vacuum tubes filling rooms, generating lots of heat, back in the '50s, '60s, and maybe into the '70s.
Susan: All the experiments were done on mainframes, on these single big computers that filled a room.
Scott: What's a mainframe?
Susan: A centralized single big computer where you may have had multiple terminals plugged into it. As time went on, they had terminal access.
Scott: This is like racks for one computer.
Susan: One big university may have that one mainframe that your PhD candidates could steal time on.
Scott: You could wait for a little computing time on.
Susan: And get their 16k program to run on.
Scott: On punch cards that they lined up.
Susan: Then as the years roll on, these things get bigger, and bigger, and bigger. And we finally see the real split happen in say the '80s, and what happened in the '80s, Scott?
Scott: Microprocessors, CPUs, the PC really. You could spend $5000 bucks, which was a lot of money at the time, maybe 25K equivalent now, but you could spend that amount of money and now you have your own computer, which was unimaginable.
Susan: At that point I think what you see-from a history of machine learning-is you see quite a few new things come out. It wasn't just that thinking changed and computation became available in the form of the PC. You're not gonna be able to do the stuff the mainframe could, but you could at least try out a lot of ideas rapidly.
Rapid prototyping is huge in every single industry, and so you see big things. You see a lot of big things in reinforcement learning coming out of the 80s. You see a lot of basic stuff being laid down.
Scott: The groundwork is being laid then.
Susan: But even then the computers still don't have what it takes to power, the ML systems of today. You see as the architectures get more RAM, more compute, you see a steady trickle of more and more come out from the 80s, through the 90s, and then the 2000s hit, and the world changed.
Scott: The Pentium 1, Pentium 2, Pentium 3, that kind of happened throughout the 90s. CPUs got bigger, better, faster, a little more memory, the hard drives got bigger, clock speeds got faster, and it sort of famously, Moore's law-that stuff happened. But then into the late 90s, mid 90s you have graphics processing units, or GPUs that start to become popular. And then mid 2000s is when NVIDIA (who is actually an investor in Deepgram) started doing Cuda. Which is very big ... Cuda. If you don't know what it is, it made it so that a normal programmer could access a GPU and use it to perform tasks in a way that they're used to.
![]() Moore's Law-named after the the famed Intel co-founder Gordon Moore-is an observation that the number of transistors on integrated circuits has doubled every year since their inception. Has that doubling of transistor number come to an end?
Moore's Law-named after the the famed Intel co-founder Gordon Moore-is an observation that the number of transistors on integrated circuits has doubled every year since their inception. Has that doubling of transistor number come to an end?
Susan: C-like interface.
It's not just hardware, infrastructure also means software
Scott: You make a nice interface, that's ike C, which is a programming language that many programmers know, but then it actually runs on the GPU. Usually what this means is very fast speed-ups for a specific tasks. Those specific tasks are like matrix operations, and things that are massively parallel.
Susan: During that period you still don't see, what we see today, but that's probably when the big research academics started taking notice. One starts seeing the beginnings of papers talking about GPUs and how they can speed up a machine. It had been done in the 90s, using GPU-like processors, it had been done through the 2000s, but it just never caught because everything single time it was hard. It's really hard. It's really specialized. They changed the hardware out and all your stuff breaks.
Scott: You had to be a machine learning expert, a data expert, a software expert, and a hardware expert in order to do any of it.
Susan: And at a certain number of experts you break. I ran out of fingers to be an expert on.
Scott: Yeah. Too many experts.
Susan: Cuda is just a game changer, and by the late 2000s, early 2010s, we are starting to see an explosion of machine learning stuff coming out. Just like when the PC came out, you no longer needed this huge server of a thousand cores to be able to do anything in a reasonable amount of time. Now you can go to your desktop, bust out a reasonably priced graphics card, and you can do amazing things. You can start recognizing cats, and once you can recognize cats...
Scott: Well people are excited then.
Susan: You're excited then.
Scott: Yeah, you identify the cat neuron.
Susan: And you can do a rapid prototyping. You've got a crazy idea, you don't have to write up a 15 page report on what you think you might gain out of this so that you can borrow a bunch of time on a huge cluster.
Scott: You just go do it, and maybe a day or 2 later you got the answer.
Susan: Yeah, and it either works or it doesn't. It's enough to go forward on.
Susan: And so you just see this massive explosion around you.
Scott: We're in particular talking about the deep learning side of machine learning but there was machine learning going on before deep learning, that's true.
Susan: Deep learning is a little subset of machine learning.
Scott: Not little.
Susan: It's a big subset, yeah.
Scott: There's a lot of hype, a lot of money dumped into it, but a lot of promising things, especially on the perception side. Like, for example, being able to see or understand the are the sorts of things that deep learning is pretty successful at. But there are other types like decision trees, and boosted decision trees, and other machine learning types that have been around for, the 80s or earlier, that you could do on CPUs, and actually are very fast. You can train them, they're quick. You can do tests, you can actually dissect them, and figure out why they made their decisions in a lot of ways. But, they usually aren't as good. Then people started to get really excited about GPUs and deep learning because once you throw enough data, and compute, and deep learning-ness at something, it starts to work really well.
Susan: Figure out your loss function, get some basic structure going.
Scott: Yeah get some basic structure going, then it's like "Wait a minute, things are starting to work really well!" and this is like late 2000s, early 2010s.
Susan: You see it on image recognition. You see the accuracy becoming amazing, error rates dropping like crazy.
It's not that suddenly brand new ideas magically appeared out of nowhere. It's the ideas that everybody wanted to do, it just took them a long time to do. They were finally able to rip through it.
Scott: This is why the infrastructure is so important, you finally got all your stuff together, your hard drives are big enough, your memory is large enough, your memory bandwidth is fast enough, your computation speed is fast enough, the number of flops that you can do is enough.
Susan: And the tools. This is again is the big thing, like Cuda-it has enabled a huge set of tools.
 Cuda was a key element in the deep learning revolution.
Cuda was a key element in the deep learning revolution.
Scott: There are layers upon layers here where there's a GPU that has hardware stuff going on inside it, but then that is abstracted away by Cuda, but then Cuda is abstracted away by other deep learning frameworks as well.
Susan: That just enables the next round, and the next round, and the next round.
Scott: It takes a cognitive load off the person who's trying to develop something. When you're going to develop something you say: I'm gonna spin up this thing, I don't even necessarily need to know how it works under the hood, but I can make it do stuff.
Susan: It's one less expert finger you need to have. I used to have all 10 expert fingers, and then slowly your strip them away.
Scott: Well now you can make progress in the one or two areas.
Susan: You can delve deep into, "I just don't care as much about those other things, I wanna care about this problem right here." So yeah, it's been an amazing roller coaster ride.
Scott: This is like the training side though, right?
Susan: You're right, the training side has been here, production side has not. There's not a tremendous production push on the GPU side in a lot of areas until recently.
Scott: Until very recently.
Susan: But that's part of the shift we're starting to see.
Scott: I think it's the inference side-which is like the production serving of these models-that lags behind because the training has to happen, your models have to work, you have to get comfortable with how they work, and then you think "Oh, maybe I should turn this into a product," and it takes a little while.
Susan: That was up till the early 2010s, mid 2010s. Now we're in the later 2010s and what are we seeing? I think we're seeing another architecture shift. What do you think?
Are we seeing another architecture shift?
Scott: Well I think the AI chip, and iPhone, people have heard about that, where you can use ML Kit to do stuff on the iPhone and it's not using the CPU anymore, or it's using a lot less.
Susan: They hope. Apple opened it up to other developers before. I think this was all enclosed and only they had access to it. Now they've opened it up to developers.
Scott: Any developer could go and try to use this chip to do something, and have it be.
Susan: That's the trend. First we had no specialized processing, and then we found the graphics world does a lot of what we need. Those big matrix math applications.
Why are GPUs so good?
Susan: GPUs do the same operations that it takes to take a 3D scene, and rotate it around, and do all these special effects there.
Scott: If you're gaming and the guy shoots this, or the plane flies here, this all has to be generated in a virtual world, and there are all the polygons, and points, but then it has to be projected onto your 2D screen.
Susan: Yep, exactly. Those same calculations, that matrix math, is also at the core of most deep learning at the moment. Deep learning has jumped, and adapted itself towards that GPU world that was in the 3D rendering world.
Scott: Scientists were using CPUs, and they're sitting there waiting, patiently tapping their fingers, saying "This is taking a long time." And, they look out and say, "What else is going on in the world? Is there anything fast out there? Is there anything that's massively parallel by any chance, because the operations that we're doing could be very parallelized." Then they see GPUs: "Wait a minute, we should be using those." It takes awhile to sort of migrate over but once you see the first little nibbles of it actually working, then the flood gates open.
Susan: The first time you go and say, well let's see what happens here - 70 times faster than what I was doing before - I think we've got something we wanna spend more time on. This is only gonna get better.
Scott: The concept for deep learning and machine learning scientists that are trying to figure out a solution to a problem, you're mostly patience limited. You can only wait a few days or maybe weeks if you're really patient, or maybe months if you're really sure it's gonna turn into something good, but you can't wait that long to get an answer to your experiment. So any speed-up you can get, even 2X you're happy about, 10X you're really happy about. But 20X, 50X, 70X on a GPU, you're just like "What? This enables so much more!"
Susan: It wasn't just one order of magnitude better, it's multiple orders of magnitude better.
That brings the point though, when machine learning came to the GPU, it wasn't the GPU came to machine learning. I think now what we're seeing is, with these specialized integrated circuits, we're seeing hardware is coming to machine, learning for the first time.
In the past, machine learning adapted to the hardware, now the hardware we're starting the hardware adapt to the machine learning. That's the revolution that's going on right now.
Everybody knows it, but not too many people are really stating that seed change. Your phone's got specialized logic in it, where we're starting to see chip manufacturers really make this a major design priority, as opposed to some little secondary thing. That's a big deal.
Scott: It's hard, it's a big expense. It's a big gamble, to say "Hey, I'm going to build a specialized chip for this thing over here. I'm gonna take 3 years and develop it, and spend many millions of dollars. The ground might shift underneath me, and because machine learning, deep learning is moving at such a fast pace, that maybe 3 years from now the thing I'm building isn't even gonna matter."
Susan: Maybe.
Scott: People have seen over the past 5 years or so, like well CNNs are a thing, Convolutional Neural Networks, Recurrent Neural Networks are a thing. For the most part, like these ML Kit type chips really focus on the CNN, making that good, because it's like image processing from like Image Net, and running those things. These typical tasks, yeah I can build those, and I can make them fast, and I can accelerate them here rather than doing it on a CPU, or having to put a GPU, kind of the middle version of it in there. It's not a CPU, GPUs a lot faster, maybe uses some power, but then I can put it on this special chip and actually get a result out of it. People have actually-people, meaning companies like Apple-have actually put their money down and said, okay we're gonna go after that.
Susan: It shows maturity, and it shows that we have enough examples floating around of what it takes to do this stuff, to understand how we need to access memory that's different than how you do it with that generic GPU. I shouldn't say generic GPU but the specialized GPU.
Scott: It feels generic now, cause they work. Things have been working for years now, but if you went back 5 years ago you'd be like "Whoa, it's all kind of, is this actually going to work?" 5 years later we're like "Yeah, yeah."
Susan: It's out of the box now.
Scott: Fine, you just buy one, you pop it in.
Susan: We now have a much better understanding of the specialized hardware environment that machine learning, deep neural networks, and that kind of world, is imposing on this hardware, and you know, the money's there, the knowledge is there, there's still risk. I don't think anyone doubts that we're gonna see major, major shifts in how machine learning works. However, these are the first stabs, and the first stabs are making huge improvements. Low powered machine learning chips sitting in your iPhone enabling amazing new things. Can you do real-time voice, can you do real-time image recognition, the whole augmented reality world has gotta be just having a field day with the ability to do real time image recognition with these things. It's going to enable a powerful new class of applications, it already has enabled powerful new classes of applications. That's direct result of making those specialized hardware bets.
Susan: This is just a natural progression, we saw this in like hard drives back in the old days. The CPU literally would have to tell them to move exactly one place or another. Then you've got controllers that started taking that logic off, and then you have whole IO subsystems, and then specialized, and specialized, and specialized.You get big gains from that but you had to have that knowledge base beforehand to figure out how to specialize correctly.
Where are the gains?
Scott: Not everything is happening on your mobile phone though. You're not using training networks there. It might just be the inference, and it's doing inference only for you locally. Add it up over everybody's mobile phone, maybe that's a lot of inference power, but still it's not going to do other things like cloud based or in your browser when you're searching a web page. These things are all places where the computation can happen. The CPU on your laptop has a certain amount of power, and computational ability, and memory available to it, and a computer in the cloud usually has more. Then on your phone it's less.
Susan: It is interesting that we're seeing a lot of great tools starting to hit on the browser front. You know, JavaScript APIs for machine learning are coming out, and when I say for machine learning, like you said it's more for the inference side.
Susan: You're gonna do your heavy lifting on a box that's got some nice requirements and all this stuff.
Scott: Yeah, you do your training on a server.
Susan: And then you make sure it can run on the browser.
Scott: Yep, and then maybe you shrink it down.
Susan: If you're doing it locally in a browser, you probably only need to recognize 1 stream of audio. You only need to recognize one image. You're not doing 10,000 streams simultaneously. But, it's just amazing to see how quickly we've gone, and how much we're now specializing, and how big. This is making hardware changes. It's carving out a niche in architectures, which is a pretty big deal.
Scott: If your phone is trying to do some inference on a chip then it has to go out and access a database on a server somewhere else in order to do the inference-it doesn't make that much sense. What it would rather do probably is just ship off the image, have that handled somewhere else, and then get the answer back.
Susan: That's a great point. You wanna put the processing power where the data is at. Because, even though we got big pipes, they may not be perfect. So you see that trend: we're pushing tools on to the phones. There's one area that is growing in leaps and bounds right now that's a big big deal, and that's the self driving car world: autonomous vehicles.
You can't process that on the cloud.
Scott: Yeah you don't want that. If your internet connection goes down, you don't want your car to stop driving.
Susan: Yeah, it's like, I'm sorry we can't drive you to grandma's house.
Scott: The buffering graphic comes up.
Susan: But there's a turn, please connect it! There's a turn!!
**Scott: Buffering, buffering.
Susan: Please stand by.
Susan: Just like on the phone front, you're really starting to see specialized hardware come out, I mean big time. NVIDIA got a great platform for that. Trying to standardize hardware and all that for doing those big problems locally.
Scott: Because you have tons of sensors and you need to have a rack to mount everything to, and so it's like just get this thing, and then now you essentially have an autonomous car. This is still more like a development kit though, right? This isn't like go buy this, put it on your car, now your car's gonna go drive itself.
Susan: This is like you're playing your PC, it doesn't mean that you can do anything with it, it just means that you've got the compute necessary to do cool things with it.
Scott: You've got the hardware. Still a lot of massaging that needs to happen.
Susan: The point is that we're specializing hardware for the machine learning applications, and no longer are we kind of begging, borrowing, stealing, from the graphics world. And the graphics world's like: "We'll make a little concession for you." Now it's full blown, big deal, making specialized stuff for it which is a huge change. It's a huge big deal. But so is this what we're gonna see? Where are we at and are we on the right path?
Is this what we're gonna see 10 years from now?
Scott: I think the time scale of 10 years, maybe there could be a change but that's a long time away.
Susan: Yeah, in internet years. In learning years.
Scott: In deep learning years. That's a long, long time away. But I think talking about the different types of devices matters. So mobile, personal computer, and server, that matters. If you're talking about training your inference, I think it matters. It's going to be hard to get away from GPUs in the server domain just because power isn't so much of an issue there, and you really want raw high functioning power that is very agile, so you can do your experiments. If you're going to have a really hard coded AI training chip, then you better not change your model very much.
Susan: You better not bring in brand new, crazy concepts. You better not bring in brand new ideas. You better stick to large numbers times large numbers plus large numbers.
Scott: Exactly, and you can train in your image net model really fast, fine, right?
Susan: That's so 2000s.
Scott: But if you're trying to do something more complicated, then you're probably not going to be able to. Like time delaying your neurons or something, that's not gonna happen on that chip. You probably can do it in a more flexible architecture. Maybe it'll be easier to do it in CPUs, hard and time consuming to train, but then morph it to a GPU-land where it can actually grow up a bit there, and then maybe you ship it off to that AI chip.
Susan: I totally one hundred percent agree with you, and for those who don't know, Scott and I have had this kind of running debate which goes: "What is the future of machine learning like?" One of my first shots across a bow with Scott was, matrix math, 10,000 wide whatever. I think that we're gonna see much incredibly more complex and fine-grained structures come out-ones that are not as compatible with today's efficient, and large matrix multiplication.
Scott: Right now, the idea is: Take whatever problem you have and think really hard so you can shoehorn it into doing a matrix multiplication. If you can do that then it'll probably be fast enough in order to train, and you can see the result.
Susan: We've taken a brand new big, high resource area of all this compute that GPUs have given us and we've adapted to that. Now that we're seeing the hardware adapt to us, I think we're going to see an explosion of new architecture ideas. There's a lot more revived interest in and thinking about the basic structure: thinking about the basic neurons going back to biology again, and pulling in new things like time delays. Of course there's pulling in brand new types of ways of connecting them. Again going down to single connections as opposed to thinking, "Oh I've got this 1024 layer, fully connected layer to it, now it's a 1024 to fully connect the layer, just because it's efficient and fits right in perfectly memory wise and all these different things." But nothing about the problem said a 1024. How do you appropriately connect these things?
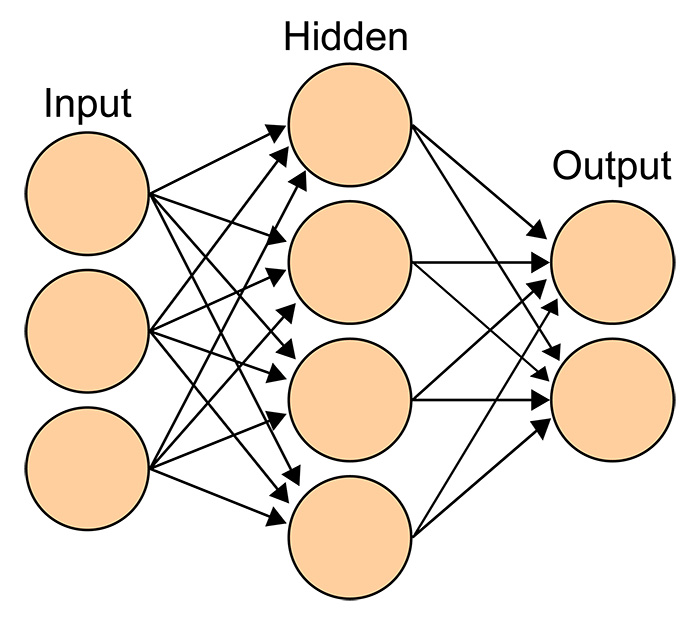
This is a representation of a generic neural network. Note the connections between the first layer of three nodes, and the second layer of four.
Susan: Now that we're merging back and we're having hardware starting to adapt to us, I think that we're going to start seeing that the current situation is an iteration number 1. By the time we get to iteration number 3 we'll be looking back at the first stuff and see that it can't run anything. This would be because we've been able to explore these crazy amazing, brand new, out there, fun, architectures.
Scott: The backwards compatibility isn't going to be that good.
Susan: You see this throughout. You make this blind stab into the future, and especially with a field that's changing so rapidly, and has so much, so far to go. It is an impossible task to pick it perfectly. It's amazing. It truly is amazing that we've had as much longevity as we've had with the tool kits, and I think that speaks to the massive, massive power gain that we got from GPUs. It's just such massive resource that we got, that we have kept using it, and not shifted it dramatically so far.
Scott: But it speaks to how large the problem is too. Hey we still use 'ye old internet too', and it's like, well things get better but it's still using similar protocols that we just kind of beefed up over time. Yeah, it's frustrating it doesn't work as perfectly as you would expect, but hey, it works. Of course, you can make advancements with it, and a similar thing will probably happen over the next 5 or 10 years with deep learning. We have all these tools, we have all this established literature, and tribal knowledge about how this stuff works, and we keep getting more and more results. But eventually you'll hit some diminishing returns. We will need to make a jump to something else.
Susan: It's an exciting time to be here, to see this stuff. Just seeing all the new worlds we can work in. The idea that you can really apply these tools in the browser, you can apply them on your phone, you can apply them on an internet of things device, you can apply them on something rolling down the road at 100 miles an hour. I don't drive at 100 miles an hour, honest.
Scott: I think, you're going to see it deployed in those areas, server, personal computer, on your phone you're already seeing it happen, but you're gonna see it just integrated more and more, and the inference especially. Training not so much, that's still gonna stay in the servers for awhile. But you know, people discuss about federated training, right like using your mobile phone or your CPU or something to train a model, but like very slowly, locally, but then aggregating all the results on a server. That might be a thing, but has not been a thing even though people have talked about it for a few years.
Susan: This is a little off-the-infrastructure-side, but these pieces of infrastructure, enabling rapid prototyping, we get breakthroughs every once in awhile that radically change the playing field. Often what we find is we were doing something incredibly inefficiently before, but because we didn't have the resources to just do that thing fast enough to try the next thing, and next thing, and next thing, it was just a huge roadblock. Had we known this one weird trick.
Susan: We could have done the things in the past.
Scott: The cost is discovering the trick.
Susan: And once you find that one weird trick. And so it's entirely possible that, or entirely probable that the next sets of revolutions will come as we find that one weird trick, and it changes everything we know about how networks work, and the best way to plug them together. We've got 5 100ths of the memory, and a thousand times the speed, just because of that one weird trick.
Scott: You already see some of the GPU side morphing a little bit, saying hey we're going to include FP16 training, which is like a lower precision training so it can train faster but while giving up precision. You see tensor cores, that are a more specialized unit instead of just the standard processing unit that they use in the GPUs, like, "Hey here's one specialized just for machine learning," but it's still pretty general. You know you see the hardware changing on the GPU side as well, just to kind of get a little closer to that specialization but without losing the flexibility.
Susan: Yeah, like I said, we start off adapting to the hardware, and now we're seeing the hardware adapt to us, and it's the circle of computer life.
Scott: The circle of life. They eat each other too and they recycle the silicone.
If you have any feedback about this post, or anything else around Deepgram, we'd love to hear from you. Please let us know in our GitHub discussions .
More with these tags:
Share your feedback
Was this article useful or interesting to you?
Thank you!
We appreciate your response.



