A Note to our Customers: OpenAI Whisper's Entrance into Voice

October 14, 2022 in Product News

Last month was big for speech intelligence as OpenAI released Whisper, a general-purpose speech recognition model. We've gotten several questions about what this means for the future of Voice AI, so we wanted to share our thoughts with you.
OpenAI Whisper is an open source speech-to-text tool built using end-to-end deep learning. In OpenAI's own words, Whisper is designed for "AI researchers studying robustness, generalization, capabilities, biases and constraints of the current model." This use case stands in contrast to Deepgram's speech-to-text API, which is designed for software developers to build highly scalable, production-quality products using voice. The consequences of these differing design objectives are evident in the offerings of both products, as will be described throughout this whitepaper.
OpenAI offers Whisper in five model sizes, where larger models provide higher accuracies at the tradeoff of increased processing speed and compute cost. At Deepgram, we know a good speech model when we see one and are impressed with the accuracy of some of Whisper's larger models. However, we also know that there are many important factors beyond accuracy that make the difference between a research-oriented tool and a tool built for highly scalable products.
Overall, our assessment of Whisper depends on your intended use case. Whisper is a great tool if you want to quickly create a demo product or conduct research on AI speech recognition. On the other hand, if your use case involves making a reliable, scalable, cost-efficient product, Whisper may not be a good fit. Its higher-accuracy models are big, slow, and expensive to run. It has a limited feature set and therefore requires its users to divert significant resources to building and maintaining additional functionality. It does not come with dedicated support options. These barriers make the decision to build with Whisper a significant commitment. For those interested in playing with the Whisper model, we've made it available through the Deepgram API — further instructions are available on our blog.
Due to the bare-bones, take-it-or-leave it nature of the offering, companies that build with Whisper must essentially commit to rebuilding the wheel that speech processing companies like Deepgram have been refining for years as their sole mission. For more complex use cases, making Whisper work in production can come at a high cost of diverting engineering, research, and product resources away from the primary mission or product. Deepgram allows users to avoid these disruptions and go straight to production with reliable, accurate, cost-efficient, fast, and feature-rich speech processing tools.
In the rest of this note, we'll provide some data and commentary on Whisper in three areas: Accuracy, Speed and Latency, and Functionality.
Accuracy
We know that accuracy is top of mind for our users. Deepgram's Enhanced model beats the highest-performing Whisper model by a wide margin — over 20%, relative — when tested on English data. Furthermore, our models achieve these accuracies at significantly faster processing speeds: on the order of 25x faster than the Whisper Medium model, which is the basis for the accuracy comparison mentioned above. We built our product to these performance standards because we know the combination of accuracy and speed is what unlocks scalability for our users.
In its documentation, the Whisper team claims that their model "approaches human level robustness and accuracy on English speech recognition." While we are impressed by their work, we encourage users to adopt healthy skepticism toward claims of human-level accuracy in speech recognition. Whisper's highest self-published accuracy statistics are below human levels of accuracy (benchmarked at 95-97%) and seem to be the result of testing on unrealistically easy audio. Real-world audio is messy: audio quality varies, background noise interrupts the dialog, speakers talk quickly with diverse accents, industry jargon and branded terms are common, etc. These natural complexities of speech should be taken into account when assessing the robustness of a speech recognition solution, but seem to be inadequately represented in Whisper's testing data set.
To give you a better sense of how Whisper and Deepgram accuracies compare on real-world audio, we conducted a side-by-side Word Error Rate (WER). For this analysis, we submitted 254 test files to Whisper and the Deepgram Enhanced model. The audio in these files feature noise, speaker accents, and long tail vocabulary typical of real-world audio data from phone calls and meetings. The files contain a range of audio durations and a range of topics, which is important when benchmarking ASR capabilities of a general model. Bear in mind that human-level accuracy can be benchmarked in the 3-5% WER range.
OpenAI Whisper
| Model Size/Tier and Relative Speed | English Word Error Rate | Multilingual Word Error Rate |
|---|---|---|
| Tiny | 15.3% | 16.2% |
| Base (.9x faster than Tiny) | 13.5% | 14.0% |
| Small (3x slower than Tiny) | 13.1% | 12.5% |
| Medium (4x slower than Tiny) | 13.2% | 12.4% |
| Large (10x slower than Tiny) | N/A: Large model only available for Multilingual | 13.2% |
Deepgram
| Model Size/Tier and Relative Speed | English Word Error Rate | Multilingual Word Error Rate |
|---|---|---|
| Base (82x faster than Large; 2.6x faster than Tiny) | 12.8% | Unique to each language offering |
| Enhanced (66x faster than Large; 7x faster than Tiny) | 10.6% | Unique to each language offering |
| Custom Trained Enhanced (66x faster than Large; 2.6x faster than Tiny) | 4.0% | Unique to each language offering |

You may have noticed that accuracy gains level off with Whisper's Medium and Large models, which might seem counterintuitive at first glance. There are several possible interpretations of this result, but the most salient is that while model size may be loosely correlated with accuracy, the correlation can be offset by a variety of factors. Our extensive research on speech processing through end-to-end deep learning suggests that when transformer models like Whisper encounter data that they aren't sure how to interpret (e.g., noisy phonecall data), they tend to generate outputs verbosely rather than being quiet. A larger model has more capacity to memorize text and be inventive, and so will tend to be more verbose in its errors, driving accuracy down.
Cost
OpenAI Whisper is not offered as a service. They only provide example code that has to be integrated into your application. It can run on either CPU or GPU resources, but CPUs are very slow for this type of workload — roughly 20x slower — so you will probably need to run your application on hosts equipped with GPU acceleration. These hosts are much more expensive and most of your application will not be able to take advantage of the GPU, meaning it will likely be very lightly utilized.
There are five different versions of the OpenAI model that trade quality vs speed. The best performing version has 32 layers and 1.5B parameters. This is a big model. It is not fast. It runs slower than real time on a typical Google Cloud GPU and costs ~$2/hr to process, even if running flat out with 100% utilization.
Beyond hosting, there are people costs associated with managing in-house speech recognition technology like Whisper. Maintaining speech recognition in-house typically demands that dedicated engineering and research teams integrate the model and regularly optimize for accuracy. Foregoing these investments can severely impact the user experience of your product or the accuracy of a downstream model. As a result, a Whisper deployment will come with $150-250k of additional cost per technical employee added to the team.
Speed and Latency
One of the major differences between Whisper and Deepgram relates to speed and latency.
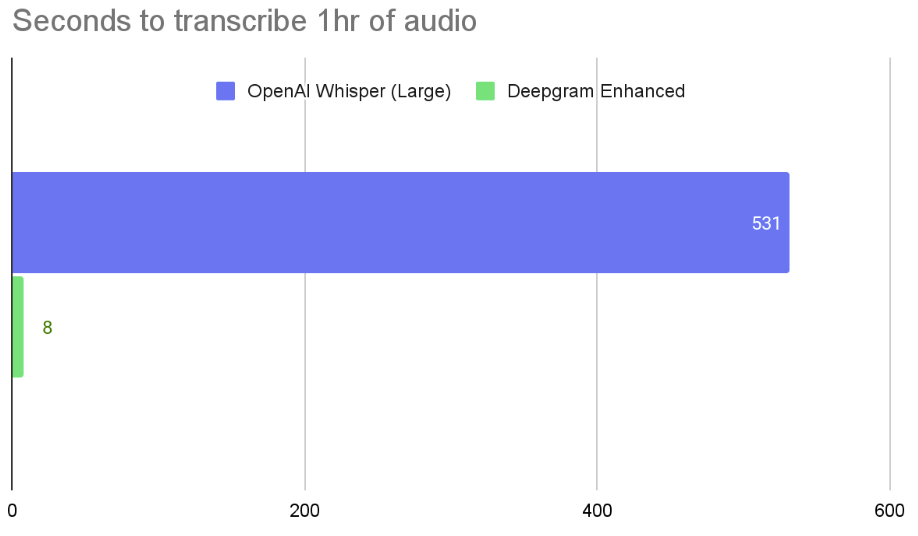
Deepgram offers batch processing for pre-recorded audio as well as real-time processing for streaming audio. OpenAI Whisper only offers batch processing for pre-recorded audio. The table below compares processing times for OpenAI Whisper on Google Cloud GPUs and Deepgram on Deepgram's GPUs:
| OpenAI Whisper | Deepgram Enhanced | |
|---|---|---|
| 1 Hour of Pre-Recorded Speech (Batch Processing) | 9 minutes (Large Model) | 8s |
| Latency (Live Streaming) | N/A - not available for live streaming | Under 300ms |
Functionality and Features
We know our users need more than just raw transcripts, so we've built rich features to help everyone get the most out of their audio. Below is a comparison of functionality and features offered by Deepgram and Whisper.
| Functionality Category | Capability | OpenAI Whisper | Deepgram Enhanced |
|---|---|---|---|
| Software Type | Closed or open source | Open Source | Closed |
| User Interface | Application Programming Interface (API) | ✅ | |
| Graphical User Interface (GUI) | ✅ | ||
| Transcription | Pre-Recorded | ✅ | ✅ |
| Live Streaming | ✅ | ||
| Language Support* | 38* | 30 | |
| Use Case Models | 1 - General | 7 | |
| Model Training | ✅ | ||
| Word Level Timestamps | ✅ | ||
| Punctuation | ✅ | ✅ | |
| Numeral Formatting | ✅ | ✅ | |
| Paragraphs | ✅ | ||
| Utterances | ✅ | ||
| Find & Replace | ✅ | ||
| Profanity Filtering | ✅** | ✅ | |
| Deep Search | ✅ | ||
| Keyword Boosting | ✅ | ||
| Interim Results | ✅ | ||
| Voice Activity Detection | ✅ | ||
| Request Tagging | ✅ | ||
| Speech Understanding | Speaker Diarization | ✅ | |
| Language Detection | ✅ | ✅ | |
| Entity Detection | ✅ | ||
| Redaction | ✅ | ||
| Summarization | ✅ | ||
| Topic Detection | ✅ | ||
| Sentiment Analysis | ✅ | ||
| Language Translation | ✅ | ✅ | |
| Speaker ID | ✅ | ||
| Enterprise Support | Hosted or Virtual Private Cloud | ✅ | |
| On-Prem Deployment | ✅ | ||
| Dedicated Customer Support | ✅ | ||
| Partner Integrations | UniMRCP | ✅ | |
| Twilio | ✅ |
* Whisper has 38 language models available at WER of 30% or less, as assessed on "easy" audio files. We consider 30% WER to be the outer limit of transcript usability, and consider WER of 15% to be the threshold of a high quality model. We therefore exclude their language models for which OpenAI's own studies indicate a WER of greater than 30%. Whisper's documentation states it achieves "strong ASR results in ~10 languages."
** Profanity Filtering is listed as a Whisper feature for English models but our testing of Whisper indicates that the filter has inconsistent performance. We recommend further testing of this feature before adoption in production settings.
The Bottom Line
For simple use cases, Whisper can be a great choice. OpenAI introduced Whisper as best suited for "AI Researchers interested in evaluating the performance of the Whisper model." It may also be a good tool for building a speech-enabled demo product, as long as the use case doesn't require streaming, advanced functionality, or large scale — and assuming that the user has GPU hosts available. Developers and companies that want to build scalable products with voice will likely gravitate toward a solution that is designed for that purpose. These differences in design become clear when you compare Whisper to Deepgram, as Deepgram offers higher accuracy, richer features, lower operating costs, faster processing speeds, convenient deployment options, model customization, dedicated support, and more.
If you have any questions about Whisper, please reach out to your Customer Success team member to discuss.
If you have any feedback about this post, or anything else around Deepgram, we'd love to hear from you. Please let us know in our GitHub discussions .
More with these tags:
Share your feedback
Was this article useful or interesting to you?
Thank you!
We appreciate your response.



