Best Speech-to-Text APIs in 2023

March 13, 2023 in Speech Trends

If you've been shopping for a speech-to-text (STT) solution for your business, you're not alone. In our recent State of Voice Technology 2022 report, 99% of respondents said they viewed voice-enabled experiences as a critical part of their company's future enterprise strategy. But the sheer number of options for speech transcription might be overwhelming if you aren't familiar with the space-from Big Tech to open source options, there's a ton of choices, with different price points and different feature sets to choose from. Although this diversity is great, it can also make it confusing when you're trying to compare different options and pick the right solution for you.
In this blog post, we're going to break down the various STT APIs available today, telling you their various pros and cons, and providing a ranking that we think accurately represents the current STT landscape. Before we get to the ranking, we're going to break down exactly what a speech-to-text API is, the core features you'd expect a STT API to have, and some key use cases for speech-to-text APIs.
What is a Speech-to-Text API?
At its core, a speech-to-text application programming interface (API) is simply the ability to call a service to transcribe audio into speech. The STT service will take the provided audio file, process it using either machine learning or a set of tools that combines machine learning with rule-based approaches, and then provide a transcript of what it thinks was said.
Key Features of Speech-to-Text APIs
In this section, we'll survey some of the most common features that STT APIs offer. The key features that are offered by each API differ, and your use cases will dictate your priorities and needs in terms of which features to focus on.
Accurate transcription - The most important thing, regardless of what you're using STT for, is accurate transcription. If you're getting back transcripts that look like MadLibs, it's unlikely you're going to get much business value from them. The absolute baseline accuracy for readable transcriptions is 80%.
Batch or pre-recorded transcription capabilities - Batch transcription won't be needed by everyone, but for many use cases, you'll want a service that you can send batches of files to to be transcribed, rather than having to do it one-by-one on your end.
Real-time streaming - Again, not everyone will need real-time streaming. However, if you want to use STT to create, for example, truly conversational AI that can respond to customer inquiries in real time, you'll need to use a STT API that returns its results as quickly as possible.
Multi-language support - If you're planning to handle multiple languages or dialects, this should be a key concern. And even if you aren't planning on multilingual support now, if there's any chance that you would in the future, you're best off starting with a service that offers many languages and is always expanding to more.
Automatic punctuation & capitalization - Depending on what you're planning to do with your transcripts, you might not care if they're formatted nicely. But if you're planning on surfacing them publicly, having this included in what the STT API provides can save you time.
Profanity filtering or redaction - If you're using STT as part of an effort for community moderation, you're going to want a tool that can automatically detect profanity in its output and censor it or flag it for review.
Topic detection - If you're looking to process large volumes of audio in order to better understand what's being discussed, a STT API that offers topic detection could be something you want to focus on.
Custom vocabulary - Being able to define custom vocabulary is helpful if your audio has lots of custom terms, abbreviations, and acronyms that an off-the-shelf model wouldn't have been exposed to.
Keyword boosting - Similar to defining custom vocabulary, keyword boosting lets you make it more likely that the STT API will predict words that are particularly important or common in your audio.
Tailored models - If keyword boosting and custom vocabulary aren't enough for your needs and you're still seeing poor accuracy, you might want to look for a provider that will let you tailor a model for your specific needs, based on your own data. This typically improves accuracy beyond what any out-of-the-box solution can.
Accepts multiple audio formats - Another concern that won't be present for everyone is whether or not the STT API can process audio in different formats. If you have audio coming from multiple sources that aren't encoded in the same format, having a STT API that removes the need for converting to different types of audio can save you time and money.
Speech-to-Text Use Cases
As noted at the outset, voice technology that's built on the back of STT APIs is a critical part of the future of business. So what are some of the most common use cases for speech-to-text APIs? Let's take a look.
Smart assistants - Smart assistants like Siri and Alexa are perhaps the most frequently encountered use case for speech-to-text, taking spoken commands, converting them to text, and then acting on them.
Conversational AI - Voicebots let humans speak and, in real time, get answers from an AI. Converting speech to text is the first step in this process, and it has to happen quickly for the interaction to truly feel like a conversation.
Sales and support enablement - Sales and support digital assistants that provide tips, hints, and solutions to agents by transcribing, analyzing and pulling up information in real time. It can also be used to gauge sales pitches or sales calls with a customer.
Contact centers - Contact centers can use STT to create transcripts of their calls, providing more ways to evaluate their agents, understand what customers are asking about, and provide insight into different aspects of their business that are typically hard to assess.
Speech analytics - Broadly speaking, speech analytics is any attempt to process spoken audio to extract insights. This might be done in a call center, as above, but it could also be done in other environments, like meetings or even speeches and talks.
Accessibility - Providing transcriptions of spoken speech can be a huge win for accessibility, whether it's providing captions for classroom lectures or creating badges that transcribe speech on the fly.
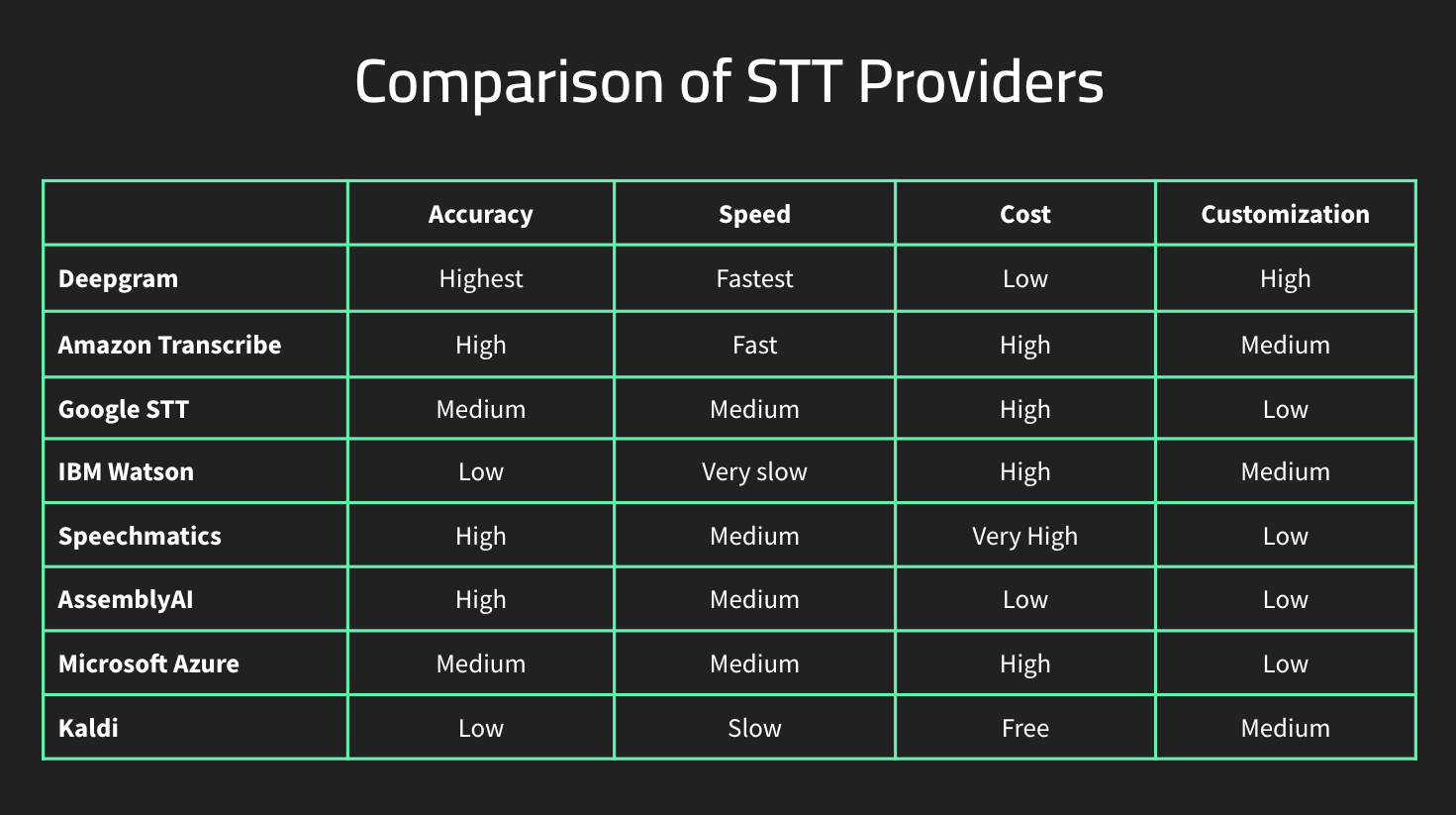
Top 9 Speech Recognition APIs
With that background out of the way, let's dive into our ranking, and what we think are the top 9 speech-to-text APIs available today.
1. Deepgram Speech-to-Text API
Summary: We might be biased, but we think Deepgram is the best STT API on the market. We're a developer-focused ASR provider with SDKs, providing an API that data scientists and developers can use to convert messy, unstructured audio data into accurate and structured transcriptions in batch or real-time-both on premises and in the cloud. Deepgram out of the box accuracies are in the 90%+ range with an option to customize speech models and reach even higher accuracies. Deepgram also has the fastest ASR in the market, with a 1200x real-time speed for batch processing and has less than a 300 millisecond lag on real-time streaming. If you'd like to give Deepgram a try, you can sign up for a free API key or contact us if you have questions.
Architecture: Built on the latest end-to-end deep learning neural networks
Pros:
Highest out-of-the-box and tailored model accuracy
Fastest speed
High customization within days
Easy to start with Console
Cons:
Fewer languages than big tech ASR, but we're regularly releasing new languages
Price: $0.25/audio hour
Newsletter
Get Deepgram news and product updates
2. OpenAI Whisper API
Summary: Released in September 2022, OpenAI Whisper’s speech models are trained for speech recognition and translation tasks. OpenAI offers Whisper in five model sizes, ranging from a few tens of millions of parameters to over 1.5 billion parameters. As an open source software package, Whisper can be a great choice for hobbyists and researchers. Users are able to quickly develop a demo product which includes transcriptions of the ten languages that Whisper can currently process, or conduct product or technical research on AI speech recognition or language translation. It may not be the right choice for projects involving real-time processing of streaming voice data, but it is a very strong contender in the market nonetheless.
Architecture: Built on transformer architecture, it works by stacking encoder blocks and decoder blocks with the attention mechanism propagating information between the two.
Pros:
Open-source software
Lower cost than big brand names
Language detection
Voice activity detection
Cons:
Can't be used for real-time transcription out of the box
No model customization
No keyword detection
Not truly "free" (see below)
Price: Free to use*
*OpenAI Whisper requires extensive computing resources you'll need to requisition yourself. Whether that’s a bank of high-end GPUs for a local deployment, or costly cloud computing credits, there are significant costs to running OpenAI Whisper at any kind of production scale.
3. Amazon Transcribe
Summary: Amazon Transcribe is a consumer oriented product coming out of the development of the Alexa voice assistant. Transcribe's command-and-response transcription for short audio is very good. Their accuracy is on the higher end of ASR providers for consumer audio data but not as good with business audio. Their speed is slow with only a 4X speed up on batch transcriptions. Limited customization can be done with their Custom Language Model or keyword boosting. Besides their general speech model, they also have a more expensive medical offering. Limited support as it is not one of their main products. Can be deployed in the cloud only.
Architecture: Traditional four-step STT model with added AI components
Pros:
Brand name
Easy to integrate if you are already in the AWS ecosystem
Good choice for short audio for command and response
Fairly good accuracy with consumer audio
Good scalability, except for costs
Cons:
Poor accuracy with business audio or audio with lots of terminology
Slow speed
Limited support
Cloud deployment only
High cost
Price: $1.44/audio hour general, $4.59/audio hour medical
4. Google Speech-to-Text
Summary: Google STT is a tiny part of their overall business. The product was initially built for their Google Home voice assistant, and their focus is more on short command-and-respond applications, similar to Amazon Transcribe. Their accuracy is middle of the road, and not one of the higher accuracy ASR systems. Their speeds is slow with only a 2.5X real time speed up on batch transcriptions. Plus, there's little option for customization with just keyword boosting allowed. Support is also very poor. Can be deployed in the cloud or on premise.
Architecture: Traditional four-step STT model with added AI components
Pros:
Brand name
Easy to integrate if you are already in the Google ecosystem
Good choice for short audio for command and response
Good scalability, except for costs
Cons:
Poor accuracy with business audio with lots of terminology
Slow speed
No support
High costs
Price: $1.44/audio hour for standard models, $2.16/audio hour for enhanced models (assumes data logging opt-out; rounded up to 15-second increments in utterances)
5. Speechmatics
Summary: Speechmatics is a UK company focused more on the UK market. Their accuracy is in the mid range but they're very slow, with a batch processing speed that is 2.5X real time. They're also one of the higher-priced ASR solutions on the market. They have limited customization with a custom library where you need to also provide the phonetic "sounds like" words for training. Can be deployed in the cloud or on premise.
Architecture: Traditional four-step STT model with added AI components
Pros:
Fair accuracy
Cons:
High cost
Slow speed
Limited customization
Price: $2.75/audio hour
Compare Speechmatics and Deepgram.
6. AssemblyAI
Summary: AssemblyAI's main advantage is their high accuracy in certain use cases that don't involve lots of terminology, jargon, or accent. Their speed is slow-4X real-time batch transcription-and adding an additional channel or other features reduces the speed even more. They have very limited customization in the form of keyword boosting, and hence it doesn't work well for terminology it's never heard or novel accents and dialects. Their language support is also very limited.
Architecture: End-to-end deep learning neural network
Pros:
High accuracy for non-technical US English
Low cost
Cons:
Difficulty with lots of terminology, jargon, and accents
Slow speed
Limited customization
Price: $0.90/audio hour
Compare AssemblyAI and Deepgram.
7. IBM Watson
Summary: IBM Watson’s STT was a good early ASR provider but has been outpaced by other providers. They have very poor accuracy, are slow, and any customization will take months to years and cost thousands of dollars. Their batch transcription speeds are 4.3X and don’t offer self training. Can be deployed in the cloud or on premise.
Architecture: Traditional four-step STT model with added AI components
Pros:
Brand name
Cons:
Poor accuracy
Slow speed
No self-training
Slow customization
Price: $1.20/audio hour
8. Microsoft Azure
Summary: Similar to Amazon and Google, Microsoft's main effort in STT has been developing a consumer product Cortana. Microsoft is trained on consumer data and is good at command-and-response, but not as good as Google or Amazon. Their accuracy is poor and on par with IBM Watson. Their speed is also slow at 4.3X real-time speed on batch. Limited customization with only custom vocabulary boosting. Can be deployed in the cloud or on premise.
Architecture: Traditional four-step STT model with added AI components
Pros:
Brand name
No real-time streaming
Good choice for short audio for command and response
Good scalability, except for costs
Cons:
Poor accuracy with business audio or audio with lots of terminology
Slow speed
Limited customization
High cost
Price: $1.40/audio hour
Compare Microsoft and Deepgram.
9. Kaldi
Summary: Kaldi isn't technically a STT API, but it is one of the best-known open-source tools, so it's worth discussing here. Because Kaldi is not a ready built ASR solution, the ASR solution needs to be built from Kaldi and trained with various audio corpora with Kaldi to have an actual ASR solution. The biggest issue with Kaldi is the training data that is available to use. If the training data matches your real-world audio well, the accuracy is fair, if not, then it will be very poor. There is no support but documentation and an open source community.
Architecture: Traditional four-step STT model with the acoustic model using AI
Pro:
Inexpensive
Cons:
Very poor real world accuracy (20-40% with public training data)
Requires a lot of self training to be usable
Speed will be very slow due to architecture
Lots of developer work needed to integrate well with your systems.
Price: $0.00/audio hour
Conclusion
There you have it-our top 9 speech-to-text APIs in 2023. We hope that this helps you demystify some of the confusion around the proliferation of options that exist in this space, and gives you a better sense of which provider might be the best for your particular use case. If you'd like to give Deepgram a try for yourself, you can sign up for a free API key or contact us if you have questions about how you might use Deepgram for your STT needs.
If you have any feedback about this post, or anything else around Deepgram, we'd love to hear from you. Please let us know in our GitHub discussions .
More with these tags:
Share your feedback
Was this article useful or interesting to you?
Thank you!
We appreciate your response.


