Hell Yes, We Have SDKs, APIs, and Docs

August 3, 2021 in Product News
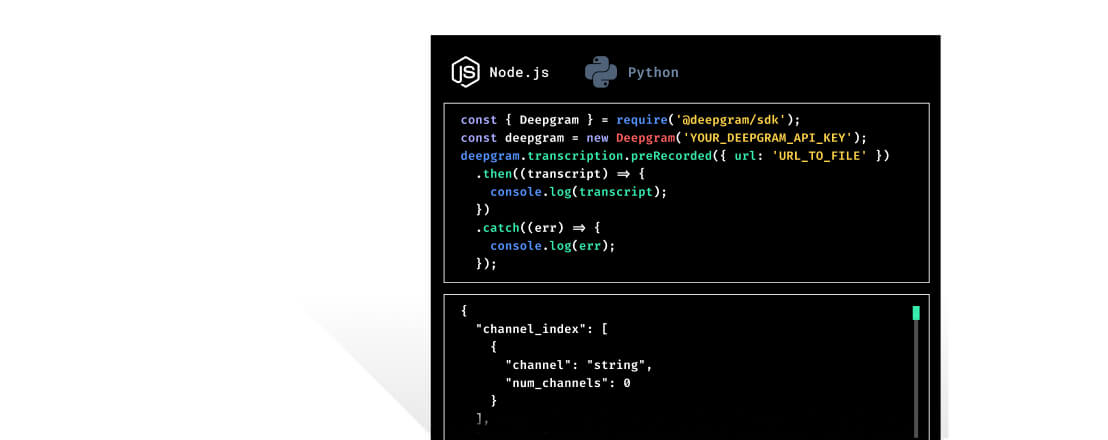
We are excited to introduce Phase One of our Developer-First initiative to help voice technology developers implement our revolutionary End-to-End AI Speech Platform more easily**.**
Issues With Legacy Speech Recognition
Voice has been one of the last unstructured data sources to be fully used and mined for insights. According to Deloitte, fully 90% of all complex conversations in contact centers are done through the voice channel and the number is not going to change anytime soon. With the pandemic, the voice channel has become even more important. In the 2021 State of ASR Report by Opus Research, 85% of organizations note that automatic speech recognition is "important or very important" to their future enterprise strategy. If audio is so important, why has it not been fully utilized in business? We believe three main issues prevent wider use of Automatic Speech Recognition (ASR) or Speech-to-Text (STT).
Costs - The cost of speech-to-text applications has gone down in the last decade because of competition, but has bottomed out due to the use of legacy speech processing that is inefficient and requires huge amounts of computing resources. The bottom of the legacy cost curve is still too high to seriously consider transcribing all of an organization's voice data.
Speed - The speed of transcriptions has also gone down, but it still takes more than one day to transcribe one day of contact center calls. Instead, organizations sample their calls to try to get some customer insights, but they often miss a gem of a product idea, can't respond quickly enough to churn signals, or can't assist sales in upselling a customer. For applications requiring real-time transcriptions, like Conversational AI voicebots, the 2-4 second legacy STT lag time does not meet their needs. You notice a one-second lag on video calls or streaming movies, think about waiting up to 4 seconds before a voicebot answers you.
Accuracy - We don't mean general out-of-the-box accuracy of all words, but the accuracy of the important keywords. Do you care if you get articles, prepositions, and filler words correct? Maybe, if a readable transcript is most important to you. But if you are doing data analysis or finding knowledge base responses, you care more about the product names, phone numbers, government ID numbers, terminology, sentiment words, and acronyms because that is where you can find the insights and intent of the conversation. Most one-size-fits-all, legacy STT solutions max out at around 80% accuracy. It's readable but unusable for things like transcribing phone numbers or social security numbers that require 100% accuracy. One digit off means incorrect answers or insights.
Deepgram reinvented STT from the ground up specifically to solve these legacy tech issues.
New Methods and Easier Access
Deepgram's STT is built with End-to-End Deep Learning, a neural network that can be trained and learn how to improve accuracy, remove noise, and focus on the important keywords. We do not use any of the legacy speech recognition processes, therefore, their cost, speed, and accuracy limitations do not apply to us. A better foundation of STT allows us to expand our focus to improve access and use of our technology. With that in mind, we are releasing the following enhancements for a better developer experience with our platform:
Two software development kits (SDKs) for Python and Node.js, with more languages to come
A new Developer Console for better API, user, project, billing, and usage management.
200 hours of free pre-recorded transcription or 150 hours of real-time streaming transcriptions with initial Developer Console sign up.
Newsletter
Get Deepgram news and product updates
Features Available
With this new Developer Console, you can try out all the following features that are included under our batch (pre-recorded) or real-time streaming price.
Interim results
Punctuation
Foreign languages
Numeral formatting
Utterance formatting
Find and replace
Profanity filter
Keyword boosting
Descriptions of these features can be found on our Product Overview page For a limited time, we are also opening up these two features at no charge.
Deep Search: Text-based search is highly inaccurate, and has big implications if it's used for NLU data classification, analytics, and automated experiences. Deep Search drastically increases accuracy with acoustic pattern matching.
Diarization: As more companies move to digital communication channels, more voices need to be identified within recordings. Diarization labels audio transcripts with specific identities to allow for better transcripts.
Happy building and keep in touch. We'd love to hear how we can keep improving your experience with Deepgram.
If you have any feedback about this post, or anything else around Deepgram, we'd love to hear from you. Please let us know in our GitHub discussions .
More with these tags:
Share your feedback
Was this article useful or interesting to you?
Thank you!
We appreciate your response.



