Deepgram Whisper Cloud: 3X Faster and 20% Cheaper Than OpenAI’s

May 25, 2023 in Announcement

TL;DR:
Deepgram offers a fully managed Whisper API that supports all five open source models.
Our API is faster, more reliable, and cheaper than OpenAI's.
We’ve also added built-in diarization, word-level timestamps, and an 80x higher file size limit.
Last month we announced Nova — the industry’s fastest, cheapest, and most accurate speech recognition model on the planet. One thing that may have been overshadowed by this groundbreaking achievement is that we also added OpenAI Whisper support to Deepgram.
Since launch, we’ve helped customers transcribe over 400 million seconds of audio with our new Whisper Cloud. If you are a Whisper user you can immediately benefit from switching to Deepgram’s fully managed solution. It’s 20% more affordable (for Whisper Large), 3 times faster, and provides transcription results with higher accuracy than what you’re currently getting. Plus, we’ve made a number of important improvements and added several standard Deepgram features – including diarization that outperforms Pyannote as well as highly accurate word-level timestamps – that OpenAI’s API lacks.
A new and improved Whisper API you can depend on
When OpenAI launched their Whisper API for speech-to-text transcription, it gained popularity despite some notable limitations:
Only Large-v2 is available via API (Tiny, Base, Small, and Medium models are excluded)
No built-in diarization or word-level timestamps
25MB file size cap and a low limit on concurrent requests per minute
No support for transcription via hosted URLs or callbacks
We've developed our own fully managed Whisper API to address these shortcomings, boosting reliability, scalability, and performance. Deepgram Whisper Cloud offers:
Availability for all Whisper models (Large, Medium, Small, Base, and Tiny)
Built-in diarization and accurate word-level timestamps at no extra cost, eliminating the burden of combining features
Support for larger files (up to 2 GB)
On-prem deployments
Deepgram’s implementation has been highly optimized for universal deployment (public/private cloud and on-prem) and integrated into a full-fledged speech and language understanding experience in a cost-efficient and scalable way using accelerated hardware. Our scalable infrastructure enables the Whisper API to handle high-traffic usage, accommodating up to 50 requests per minute (or 15 concurrent requests) for consistent reliability, and resulting in 3x faster speed for Deepgram Whisper Large.
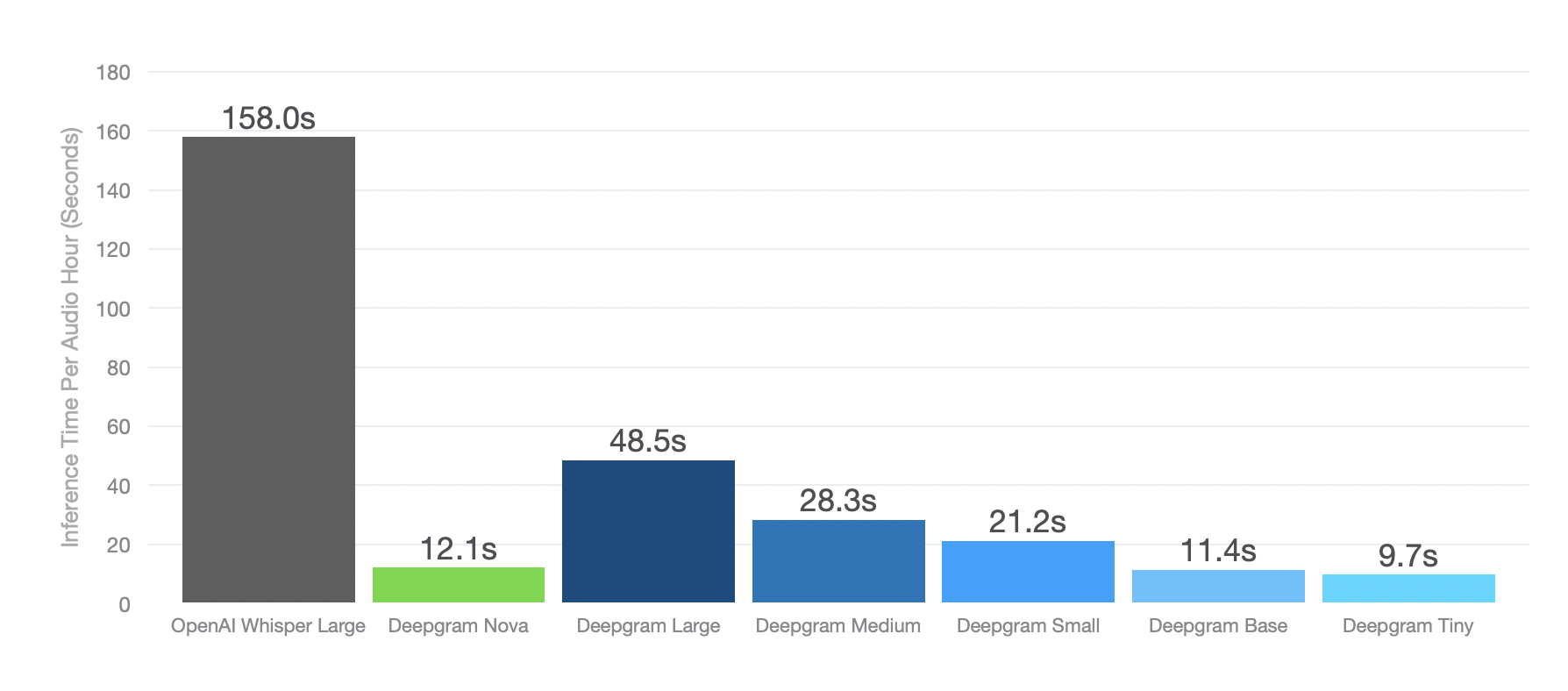 Figure 1: The median inference time per audio hour across Whisper model sizes.
Figure 1: The median inference time per audio hour across Whisper model sizes.
Our researchers also developed corrections in the inference pass for a number of known Whisper failure modes (e.g. hallucinations, issues with silent segments, repetition in the output, etc.), resulting in an architecturally improved implementation that delivers 7.4% fewer word errors[1] than OpenAI's Whisper Large API based on our benchmarks. And Deepgram’s API maintains the functionality developers expect, like various codecs, high-throughput processing, callbacks, and hosted file processing.
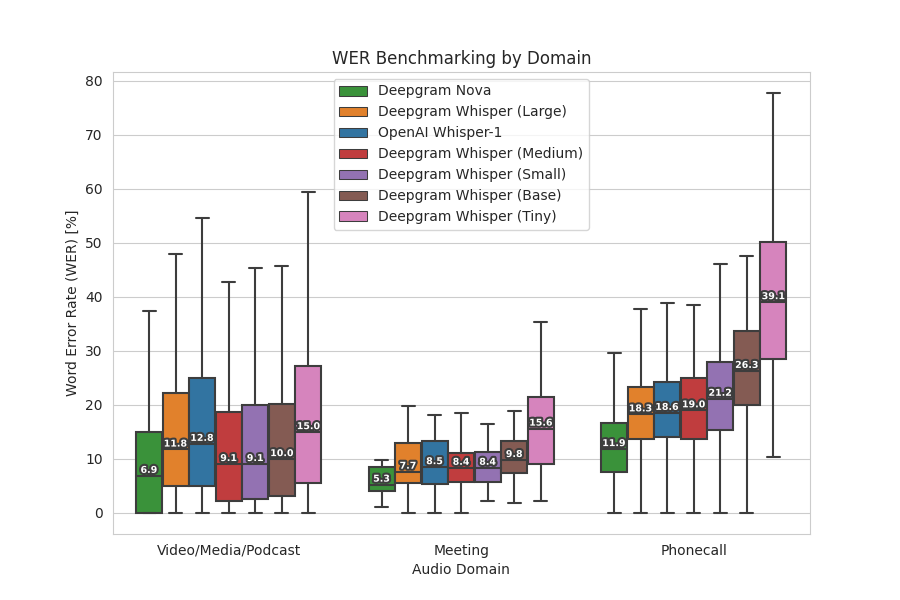 Figure 2: The figure above compares the average Word Error Rate (WER) of our Nova and Whisper models with OpenAI’s Whisper Large model across three audio domains: video/media/podcast, meeting, and phone call. It uses a boxplot chart, which is a type of chart often used to visually show the distribution of numerical data and skewness. The chart displays the five-number summary of each dataset, including the minimum value, first quartile (median of the lower half), median, third quartile (median of the upper half), and maximum value.
Figure 2: The figure above compares the average Word Error Rate (WER) of our Nova and Whisper models with OpenAI’s Whisper Large model across three audio domains: video/media/podcast, meeting, and phone call. It uses a boxplot chart, which is a type of chart often used to visually show the distribution of numerical data and skewness. The chart displays the five-number summary of each dataset, including the minimum value, first quartile (median of the lower half), median, third quartile (median of the upper half), and maximum value.
And the best part? Our Deepgram Whisper "Large" model (OpenAI's large-v2) starts at only $0.0048/minute, making it ~20% more affordable than OpenAI's native offering.
To learn more, please visit our API Documentation, and you can immediately try out our Whisper Cloud model in our API Playground.
If you have any feedback about this post, or anything else regarding Deepgram, we'd love to hear from you. Please let us know in our GitHub discussions or contact us to talk to one of our product experts for more information today.
Footnotes
[1] For OpenAI, the accuracy/WER analysis was performed on a distribution of files of shorter duration due to the file size limitation of the OpenAI API.
Newsletter
Get Deepgram news and product updates
If you have any feedback about this post, or anything else around Deepgram, we'd love to hear from you. Please let us know in our GitHub discussions .
More with these tags:
Share your feedback
Was this article useful or interesting to you?
Thank you!
We appreciate your response.
![Blog title image for the blog post: [DEMO VIDEO] Vonage and Deepgram Partner to Unlock the Power of Voice](https://a-us.storyblok.com/f/1001320/2400x1260/23eff3c0dd/2306-deepgram-vonage-partnership-blog-2x-1.png)

