Introducing Nova: Next-Gen Speech-to-Text with Unmatched Performance

April 13, 2023 in Announcement

Share
In this blog post
tl;dr:
We’re introducing our next-gen speech-to-text model, Nova, that surpasses all competitors in speed, accuracy, and cost (starting at $0.0043/min). We have legit benchmarks to prove it.
We are launching a fully managed Whisper API that supports all five open-source models. Our API is faster, more reliable, and cheaper than OpenAI's. It also has built-in diarization, word-level timestamps, and an 80x higher file size limit.
Sign up now to get started with our API and receive $200 in credits (around 45,000 minutes), absolutely free! If you're building voice apps at scale, contact us for the best pricing options.
Meet Deepgram Nova: The New Benchmark For Speech-to-Text
Introducing Deepgram Nova, the world's most powerful speech-to-text model. Compared to its nearest competitor, Nova delivers:
A remarkable 22% reduction in word error rate (WER)
A blazing-fast 23-78x quicker inference time
A budget-friendly 3-7x lower cost starting at only $0.0043/min
Nova's groundbreaking training spans over 100 domains and 47 billion tokens, making it the deepest-trained automatic speech recognition (ASR) model to date. This extensive and diverse training has produced a category-defining model that consistently outperforms any other ASR model across a wide range of datasets (see benchmarks below).
While other models rely on smaller, tightly paired audio-text training datasets or unsupervised audio pre-training, Nova's vast and diverse training data sets it apart. This means Nova doesn't just excel in one specific domain—it's your go-to model for versatility and adaptability.
To put it simply, Nova sets a new standard in ASR technology. Its comprehensive training on diverse data makes it the most reliable and adaptable model on the market, ideal for a wide array of voice applications that require high accuracy in diverse contexts. And it doesn't stop there: Nova also provides a solid foundation for fine-tuning in specific domains and tackling enterprise use cases, no matter the niche.
Performance: Measuring Nova’s ASR Accuracy, Speed, and Cost
Let’s look at how Deepgram Nova stacks up against other speech-to-text models.
Accuracy: Lowest Word Error Rate (WER)
We ran the gauntlet on Nova. Unlike other benchmarks based on pre-cleaned audio data from a select few sources, we compared Nova against its competitors on 60+ hours of human-annotated audio pulled from real-life situations, encompassing diverse audio lengths, accents, environments, and subjects. This ensured a practical evaluation of its real-world performance.
Using these datasets, we calculated Nova's Word Error Rate (WER)[1] and compared it to other prominent models. The results show Nova achieves an overall WER of 9.5% for the median files tested, representing a 22% lead over the nearest provider (see Figure 1).
 for overall aggregate across all audio domains.") Figure 1: Median file word error rate (WER) for overall aggregate across all audio domains.
Figure 1: Median file word error rate (WER) for overall aggregate across all audio domains.
Our benchmarking was conducted across four audio domains. Nova outperforms commercial ASR models and open-source alternatives like Whisper when dealing with real-world data. This highlights Nova's outstanding accuracy and establishes it as a leading choice for diverse speech recognition applications.
 Figure 2: The figure above compares the word error rate (WER) of our Nova model with other popular speech-to-text models across four audio domains: video/media, podcast, meeting, and phone call. It uses a boxplot chart, which is a type of chart often used to visually show the distribution of numerical data and skewness. The chart displays the five-number summary of each dataset, including the minimum value, first quartile (median of the lower half), median, third quartile (median of the upper half), and maximum value.
Figure 2: The figure above compares the word error rate (WER) of our Nova model with other popular speech-to-text models across four audio domains: video/media, podcast, meeting, and phone call. It uses a boxplot chart, which is a type of chart often used to visually show the distribution of numerical data and skewness. The chart displays the five-number summary of each dataset, including the minimum value, first quartile (median of the lower half), median, third quartile (median of the upper half), and maximum value.
Speed: Hands-Down the Fastest Model
To assess Nova's performance in terms of inference speed compared to traditional providers, we conducted multiple inference trials (between 10 and 100) for each model/vendor involved in the comparison. Speed tests were performed using longer audio files[2], with diarization included where offered.
We then compiled aggregate inference speed statistics from the resulting turn-around times (TAT). We compared them to how fast our Nova models completed the same tasks within the same parameters.
We found that Nova outperformed all other speech-to-text models, delivering an impressive median inference time per audio hour of 12.1 seconds, at least 23 to 78 times faster than comparable vendors offering diarization.
 Figure 3: The median inference time per audio hour was determined using longer files, and diarization was included where applicable. To ensure a fair comparison, results are based on numerous trials of the same file for each vendor, giving them a fair opportunity to showcase their performance.
Figure 3: The median inference time per audio hour was determined using longer files, and diarization was included where applicable. To ensure a fair comparison, results are based on numerous trials of the same file for each vendor, giving them a fair opportunity to showcase their performance.
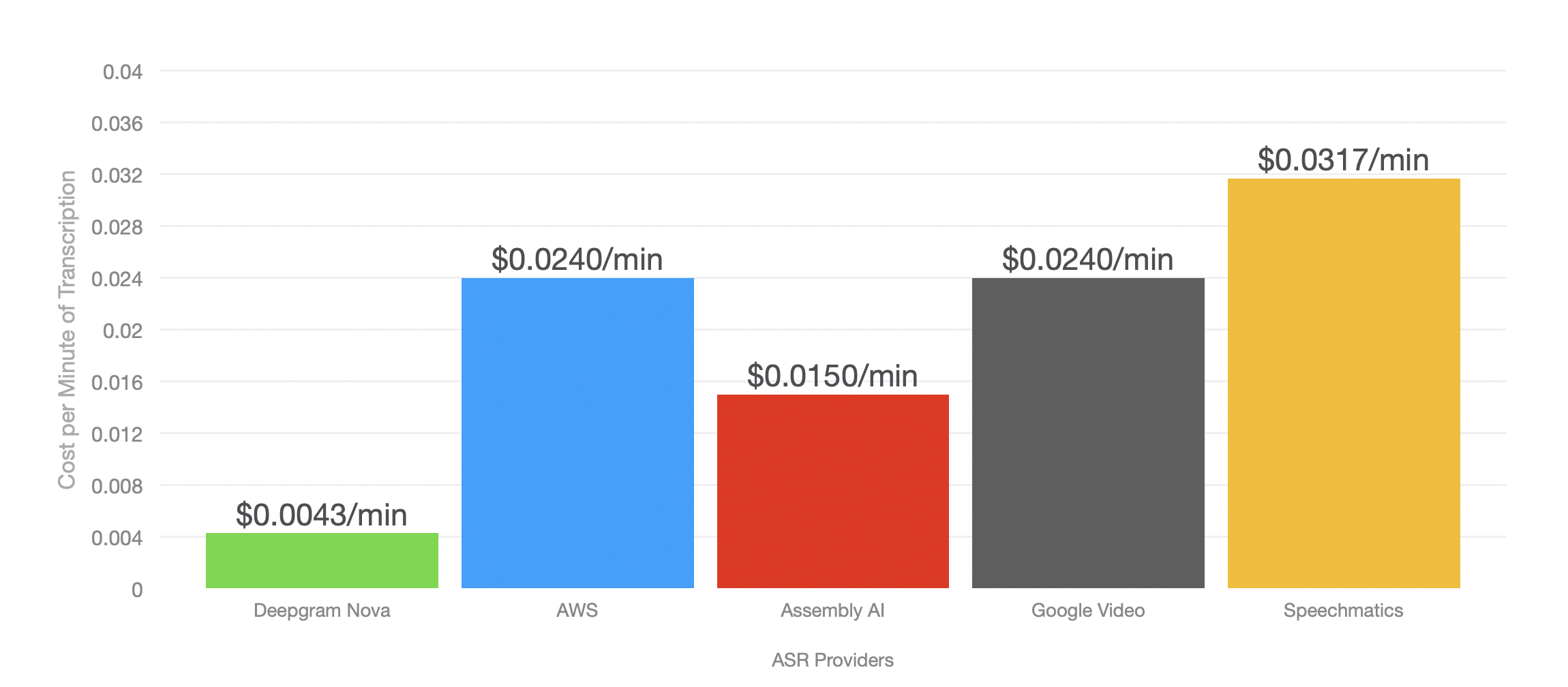
Cost: The most affordable ASR model in the market
At Deepgram, we are committed to constantly pushing boundaries in language AI. Nova is not only blazing-fast and ultra-accurate, but it also helps lower your costs. Our next-generation models achieve new levels of efficiency, which translates to cost savings for you.
Deepgram Nova starts at just $0.0043 per minute and is 3-7x more affordable than any other full-functionality provider (based on currently listed pricing).
Our Approach
Nova's outstanding performance in various domains stems from optimizing the Transformer architecture, applying advanced data preparation techniques, and using a meticulous multi-stage training approach.
Our model optimization is based on an abstraction of the popular transformer architecture, which divides it into two generalized components:
Acoustic Transformer: Encodes input audio waveforms into a sequence of audio embeddings
Language Transformer: decodes the audio embeddings into text, given some initial context from an input prompt
Information flows between these sub-networks through a universal attention mechanism that combines and fuses useful representations from different depths in the Acoustic Transformer network.
 Using proprietary architecture characterization algorithms, we identified weak points in the transformer architecture that led to suboptimal performance in both accuracy and speed for audio transcription.
Using proprietary architecture characterization algorithms, we identified weak points in the transformer architecture that led to suboptimal performance in both accuracy and speed for audio transcription.
Our team then leveraged our massively-scaled distributed compute infrastructure to explore the architecture space and identify dozens of architecture innovations. We optimized the Acoustic and Language components separately, designing the arrangement of layer types within the transformer blocks and distributing capacity across the network. These advances led to drastic breakthroughs in model accuracy without sacrificing speed.
Further, Nova achieves exceptional accuracy across various data domains through a multi-stage training approach. Initially, the model is trained using a vast dataset of unique audio data in a weakly supervised manner. Then, it undergoes fine-tuning in multiple stages with carefully curated, high-quality, domain-specific data. This meticulous process empowers the model to achieve unparalleled accuracy in areas important to our customers.
These major advances result from years of dedicated research, large-scale distributed training, and in-house data labeling expertise.
Introducing our fully managed Whisper API with built-in diarization and word-level timestamps
Last month, OpenAI launched their Whisper API for speech-to-text transcription, gaining popularity despite some limitations:
Only Large-v2 is available via API (Tiny, Base, Small, and Medium models are excluded)
No built-in diarization or word-level timestamps
25MB file size cap and a low limit on concurrent requests per minute
No support for transcription via hosted URLs or callbacks
We've developed our own fully managed Whisper API to address these constraints, boosting reliability and scalability. Today, we’re excited also to announce Deepgram Whisper Cloud, which offers:
Availability for all Whisper models (Large, Medium, Small, Base, and Tiny)
Built-in diarization and word-level timestamps at no extra cost, eliminating the hassle of combining features
Support for larger files (up to 2 GB)
On-prem deployments
Our scalable infrastructure enables the Whisper API to handle high-traffic usage, accommodating up to 50 requests per minute or 15 concurrent requests for consistent reliability.
Deepgram’s API maintains the functionality developers expect, like various codecs, high-throughput processing, callbacks, and hosted file processing.
Deepgram Whisper Large is 3x faster and with about 7.4% fewer word errors[3] than OpenAI's Whisper Large API based on our benchmarks.
 The best part? Our Deepgram Whisper "Large" model (OpenAI's large-v2) starts at only $0.0048/minute, making it ~20% more affordable than OpenAI's offering.
The best part? Our Deepgram Whisper "Large" model (OpenAI's large-v2) starts at only $0.0048/minute, making it ~20% more affordable than OpenAI's offering.
What’s next: The future of language AI is domain-specific
At Deepgram, we believe that speech is the hidden treasure within enterprise data, waiting to be discovered. Our mission is to make world-class language AI not just a possibility but a reality for every developer through a simple API call.
We've processed over 10,000 years of audio for trailblazing customers like Citi, TIAA, TalkDesk, Observe AI, Twilio, and Spotify, even transcribing NASA's radio communications between the ISS and Mission Control. We've served nearly 2 trillion enriched, computable words to our customers.
Our groundbreaking Nova is the industry's deepest neural network for speech AI, but we refuse to rest on our laurels. While large language models (LLMs) captivate the world with flashy demos, Deepgram is dedicated to delivering practical language AI solutions for businesses. The future demands more specialized approaches, such as domain-specific language models (DSLMs), which provide unmatched accuracy and cost efficiency compared to larger, more unwieldy models. If you share in our vision, let’s talk!
We firmly believe that language is the key to unlocking AI's full potential, shaping a future where natural language is the backbone of human-computer interaction. As pioneers in AI-powered communication, Deepgram is committed to transforming how we connect with technology and each other.
Keep an eye out for more exciting announcements to come!
Footnotes
[1] To compare speech-to-text models accurately and obtain an objective score that corresponds to people's preferences, we first ensured that the output of each model followed the same formatting rules by running it through Deepgram's text and style guide normalizer.
[2] We attempted to standardize speed tests for all Automatic Speech Recognition (ASR) vendors by using files with durations longer than 10 minutes. However, OpenAI's file size limitations prevented us from submitting longer files. Therefore, the turnaround times shown for OpenAI in this analysis are based on the types of shorter audio files that can be successfully submitted to their API.
[3] For OpenAI, the accuracy/WER analysis was performed on a distribution of files of shorter duration due to the file size limitation of their API.
If you have any feedback about this post, or anything else around Deepgram, we'd love to hear from you. Please let us know in our GitHub discussions .
More with these tags:
Share your feedback
Was this article useful or interesting to you?
Thank you!
We appreciate your response.
![Blog title image for the blog post: [DEMO VIDEO] Vonage and Deepgram Partner to Unlock the Power of Voice](https://a-us.storyblok.com/f/1001320/2400x1260/23eff3c0dd/2306-deepgram-vonage-partnership-blog-2x-1.png)


